Attention 崩溃真相:不除以√d,大模型为啥翻车?
前言
最近在做 GPT-2 微调时,注意力矩阵突然变得“过于自信”——最大的那个 token 几乎拿下一切权重,模型无法学习其他信息。这背后,竟只差一个看似微小的 缩放。
softmax是attention机制中绕不过的一个重要函数,其重要而又神奇。在它作用的序列里面有比较大的数存在的时候,它会表现出0即1的性质;而当序列方差小,均值也适中的时候,它作用后的序列概率分布比较均匀:
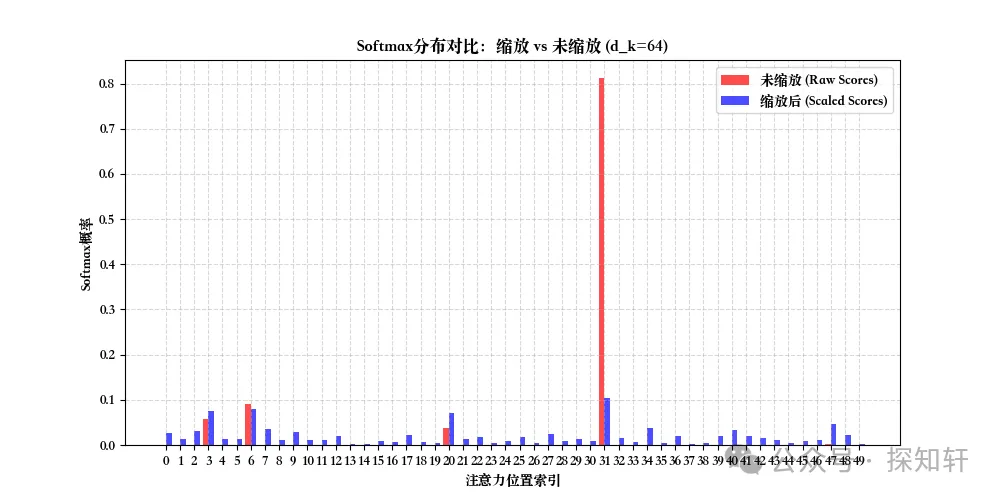
上图对比了从标准正态分布里面采样的50个值不使用和使用进行缩放得到的概率值的分布。可以看到,进行了缩放之后,更多的值都有大于0的概率,整体分布比较均匀;而没有作用缩放的情况下,有一个单峰特别大,其它地方也只有少数几个位置有明显大于0的值,其它地方的概率基本都等于0。
❝感兴趣的同学可以自行看代码调试和修改:https://gist.github.com/llmdelver/1a44529995934e7c05be97cba820e3d4
我们在文章
Attention之旅--浅谈self attention和multi-head attention
中提到了和计算attention score的时候会除以,其中是一个head的维度,也就是计算结果是
我们也在那里简单提了一下除以是为了减小矩阵的方差。
本文将从程序员直觉、数学原理和实战对比三大维度,带你真正理解为什么没了这一步,Attention 就要“罢工”。
程序员直觉:缩放能防止 Softmax “一言堂”
结论:未经缩放的 会因方差过大,导致 Softmax 输出近 One-Hot。


为什么要缩放?attention本质上是想要做加权平均,而这个加权平均是想让更多的token的值都有一定贡献,也就是我们不大愿意只是选择一个token的值。再结合前言的图,要做缩放,就那就是缩放前的值整体比较大,想把值整体调小来减小均值和方差。所以我们需要找到证据来说明缩放前的值整体比较大就可以了。
缩放是对矩阵中的每个元素进行作用,而矩阵中每个元素都是点积得到的,点积会涉及到维度大小相关的累加。直观来看,越大,累加的和越大,而和太大了可能就超出了softmax正常工作的范围,softmax就罢工了,不给你0就给你1。这一罢工,会导致下面两个直接后果:
Softmax输出接近One-Hot,模型只能关注极少数Token,失去全局信息整合能力; 梯度消失:极端概率导致反向传播时梯度趋近于0。
这两个结果都不是我们想要的。直观来看,要想softmax不罢工,就需要处理的缩放问题。
这样凭着程序员的直觉,使用缩放就是要让softmax作用的序列的均值和方差都减小,进而增加权重的均衡性。
数学原理
假设attention模块的输入是,我们有
缩放前的值(注意,这里只是为了方便分析,实际上我们计算attention score的时候是需要按照attention head拆分之后才能做的,而不是这样简单的矩阵乘)关联了,以及它们乘起来之后的值。
这说明,要分析缩放因子,需要分析的分布特征, 的分布特征,以及的分布特征。基于此,本文从以下几个方面进行探索来试图得到缩放因子为的合理解释:
在使用了Layernorm(RMSNorm)的情况下的分布; 的初始化方法对的分布的影响; 矩阵里面的每个值跟的关系。
Norm尽量减小方差增长
基于transformer的模型基本都会使用norm,但是norm的位置并不一致。
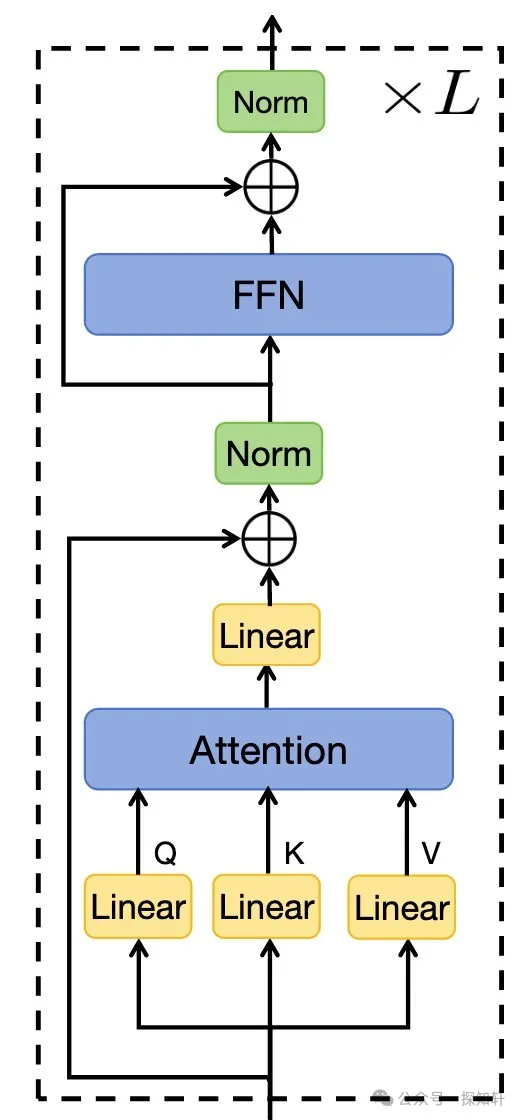
LLama这些模型里面更多使用的是pre-norm:
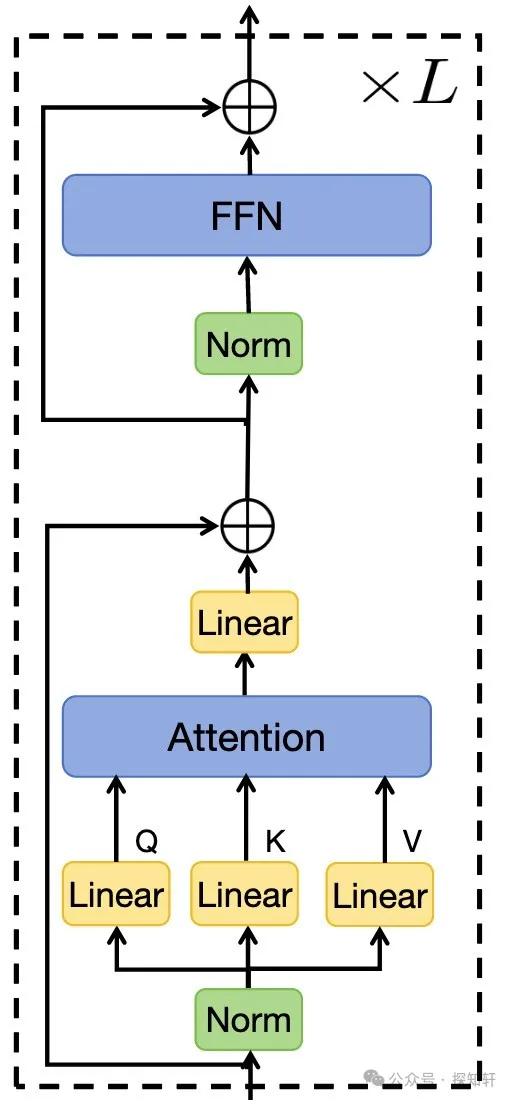
而最近很多模型,包括wan 2.1,会使用qk-norm。下图是一个qk-norm+pre-norm的结构
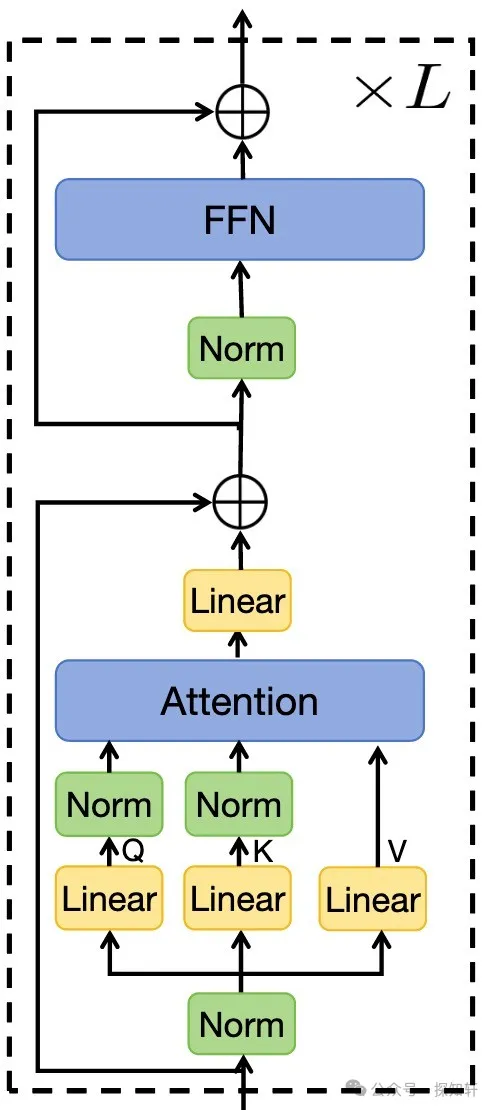
具体的Norm大致有LayerNorm和RMSNorm。
LayerNorm的公式为
其中,是输入向量均值,是标准差,γ 和 β 是可学习的缩放与偏移参数。
在最简单的情况下(),layernorm不管输入是什么样,都会把它变成均值为0,方差为1的分布。在其它情况下,均值和方差都会稍微改变,但是整体上变化不会很大。
layernorm本质上是消除特征的量纲差异,稳定梯度传播。
Transform的原始论文和早期基于transformer的模型,都是使用layernorm。而最新的一些模型则使用RMSNorm更多,其公式为:
其中在均值为0的时候退化为方差。 RMSNorm通过均方根值缩放输入,保留原始均值信息,但方差被归一化。
两者简单对比如下
| 特性 | LayerNorm | RMSNorm |
|---|---|---|
| 均值 | ||
| 方差 | ||
| 参数复杂度 | ||
| 计算开销 | ||
| 适用场景 |
总体来说,两种norm都会使得参数的方差变小,接近1。
所以我们一个基本的结论就是:在transformer的结构里面,由于使用了各种norm,输入到attention模块的数据整体上行方向的方差比较小。也就是说,每一行的数据比较大,跟输入关系不是特别大。
接下来我们继续看参数矩阵是否会放大参数的值。
参数矩阵初始化让方差保持稳定
我们在详细分析之前首先看一下各种模型都使用什么方法来进行初始化:
在我们关注的中,基本上都是使用Xavier和Normal进行初始化。下面我们对这两种方法进行深入分析。
深度网络在训练早期常因 梯度逐层传递后迅速衰减(梯度消失)或 累积放大(梯度爆炸)而难以收敛。Glorot & Bengio 在论文中指出,如果不对权重进行恰当初始化,网络输入信号 的方差会随着层数增加成指数级缩放,导致训练失效 Understanding the difficulty of training deep feedforward neural networks。他们的解决方案是 通过控制权重分布方差 使得每一层的输出方差 与输入方差 保持大体相同,从而稳定信号流动。
正态分布记为,其中表示均值,表示方差。均匀分布的均值为,方差为
所以,同理。所以正态分布如果使用均值和方差表示可以表示为
对于两个独立随机变量, 论文
如果假设随机变量的均值均为0, 那么有
假设
由于是独立同分布的,所以
为了使得输入输出的方差基本一样,我们需要保证
也就是。
上面的是全连接层该层的输入单元数目,我们一般使用fan_in表示。同理,我们还把全连接层输出单元数表示为fan_out。上面的方差可以表示为
如果我们考虑反向传播的话,可以得到
综合起来,Xavier Initialization使用下面的方差
我们使用零均值参数来做初始化,也就是中。使用均值和方差表示,其中。所以
我们可以看一下pytorch的实现,恰好可以和上面的推导契合(默认gain为1的时候,如果不为1,需要对上下界都进行缩放):
def xavier_uniform_(
tensor: Tensor,
gain: float = 1.0,
generator: _Optional[torch.Generator] = None,
) -> Tensor:
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
std = gain * math.sqrt(2.0 / float(fan_in + fan_out))
a = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation
return _no_grad_uniform_(tensor, -a, a, generator)
我们写个小程序来检验一下xavier初始化的的效果,输入是从标准高斯分布采样的值,然后经过若干不带其它激活函数的线性层,统计每个线性层输出的分布
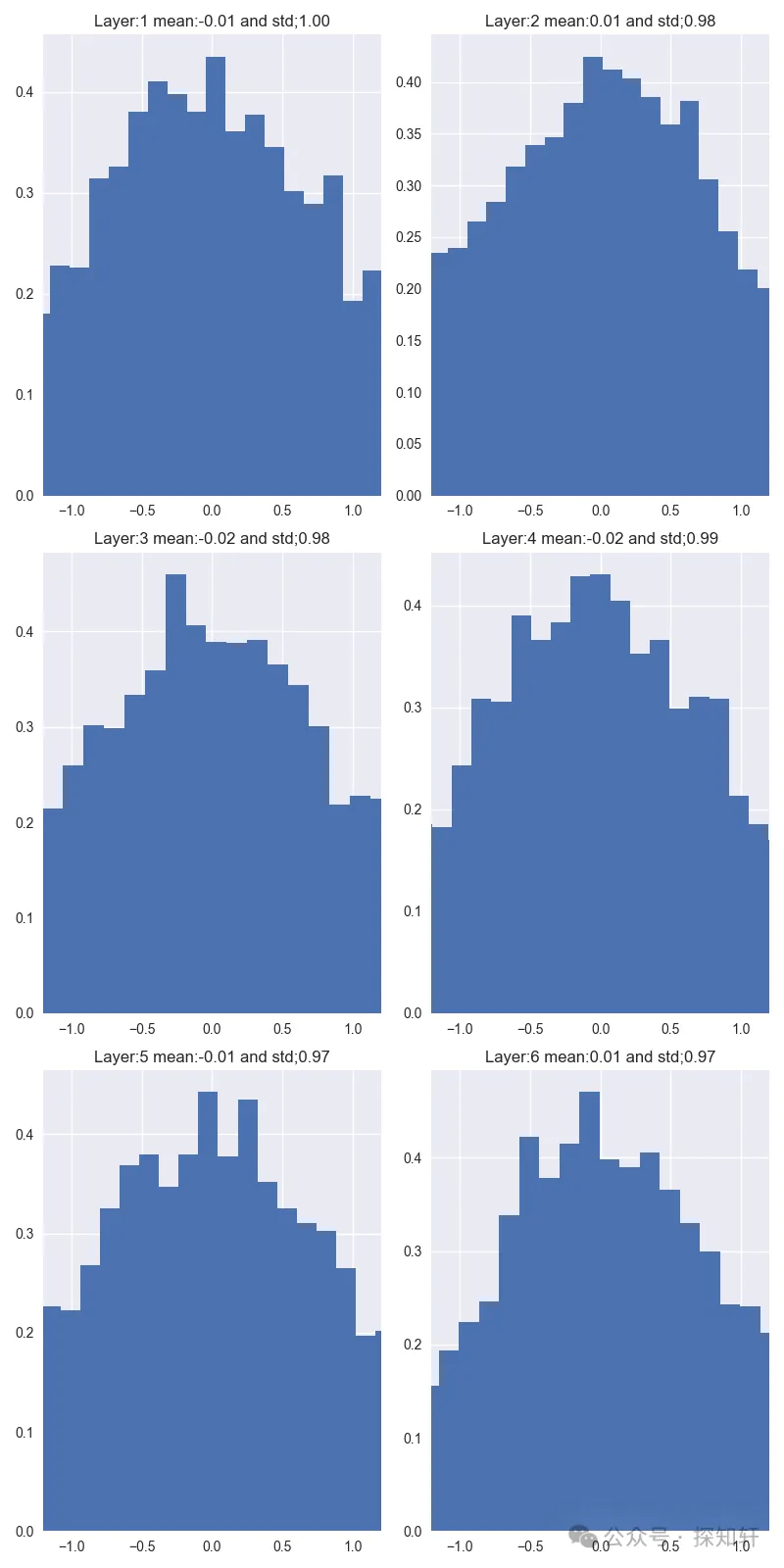
如果我们从每个层的均值和方差重新采样,叠加到一起可以得到下面的图:
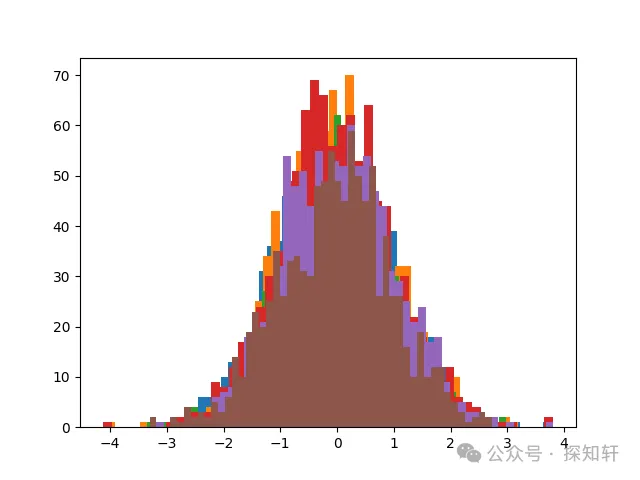
可以看到,xavier方法确实能够很好保证输入输出方差的稳定,让模型随着深度的增加而不至于发生参数的退化。
如果我们不使用xavier方法,而是每一层都使用均值为0,方差为设定值的高斯分布会怎么样呢?
如果使用方差为1,我们可以得到
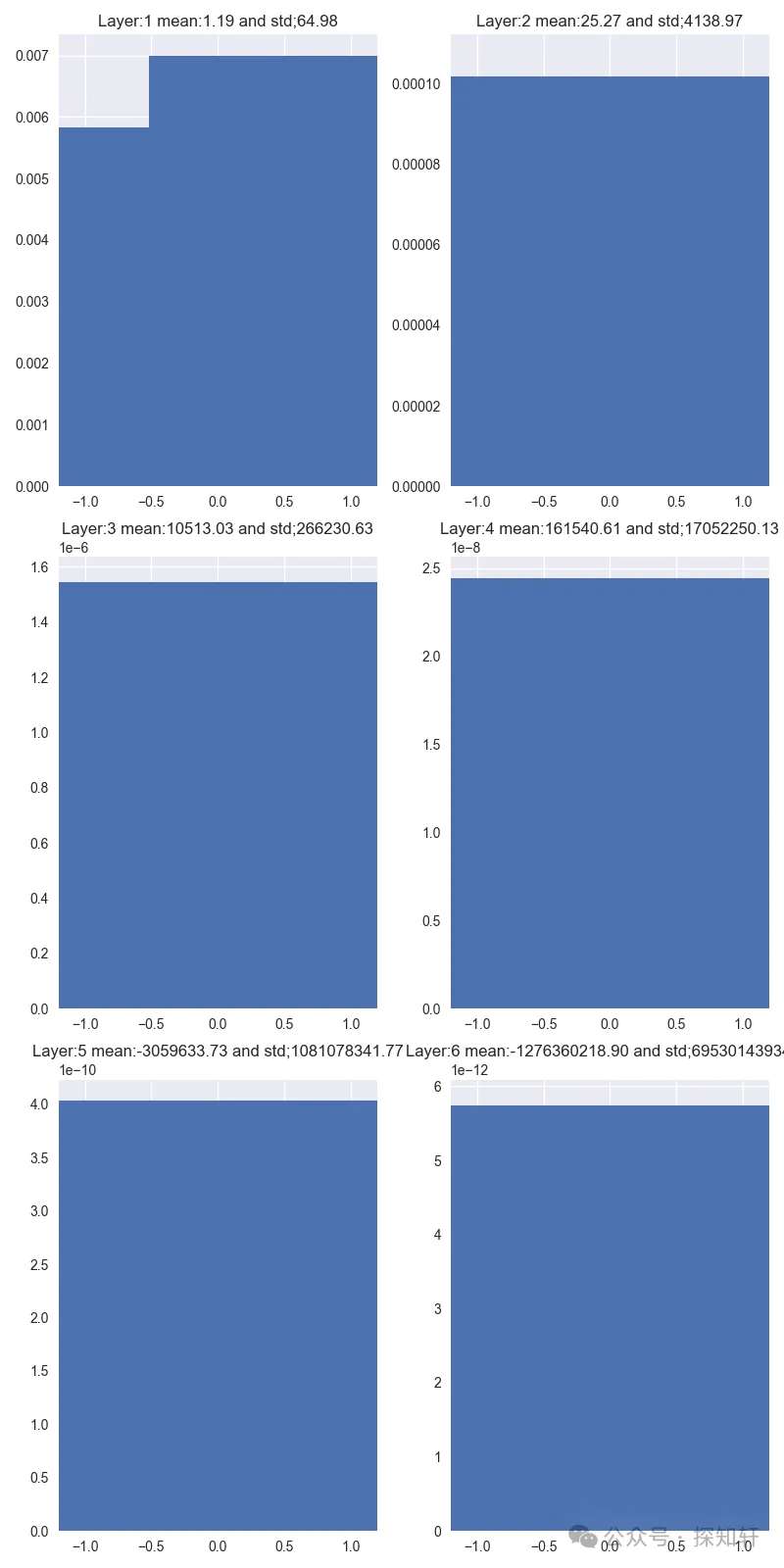
非常恐怖,均值和方差随着层数的增加都变得非常大,导致基本无法正常训练。
那如果是我们常用的均值为0,方差为0.02的模式呢?
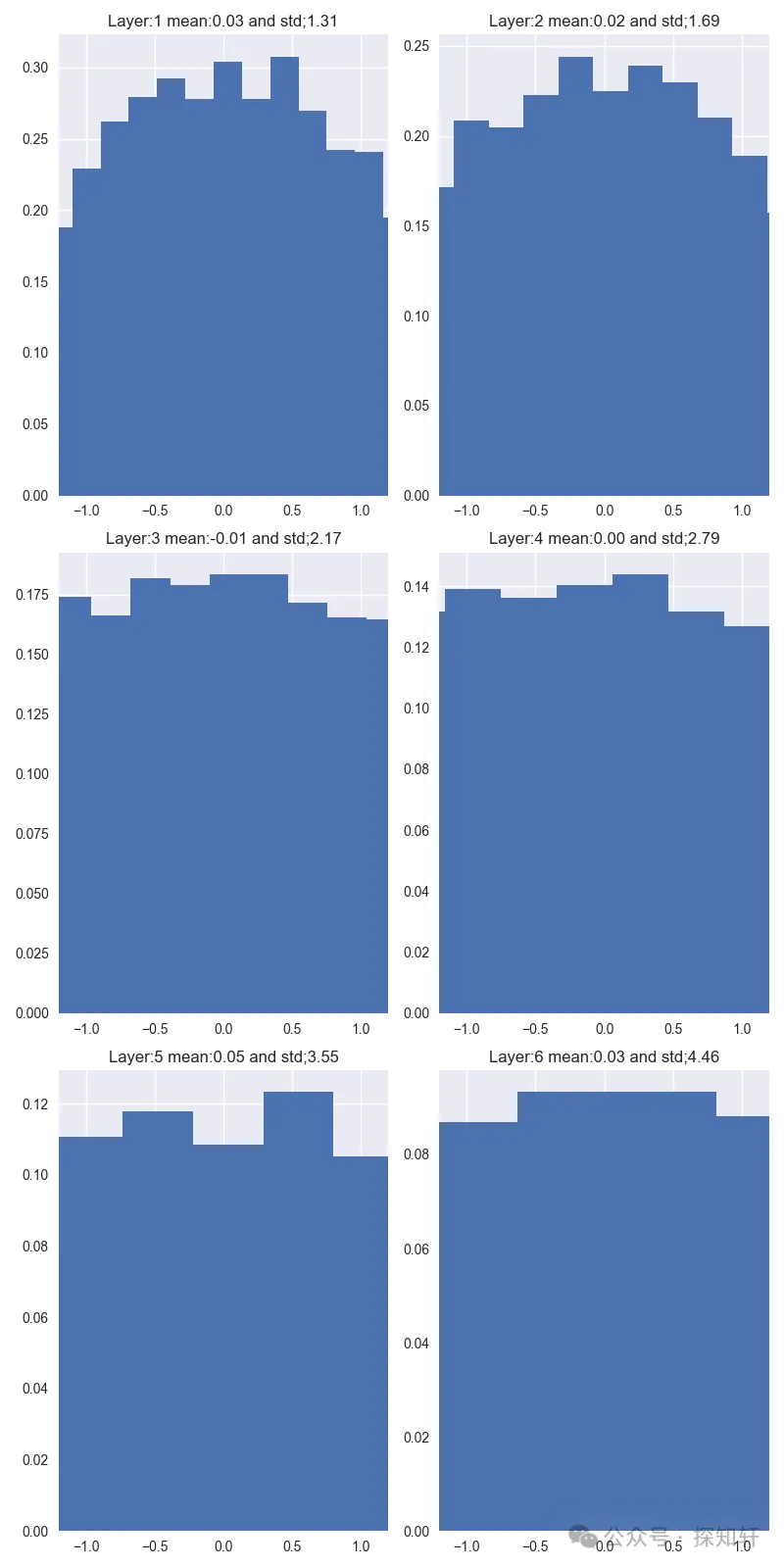
可以看到,均值保持比较好,方差会增大,但是增长很缓慢。在这种情况下,再加上layernorm(rmsnorm)的共同作用,基本可以保证模型可以很好地训练。
那如果方差呢?
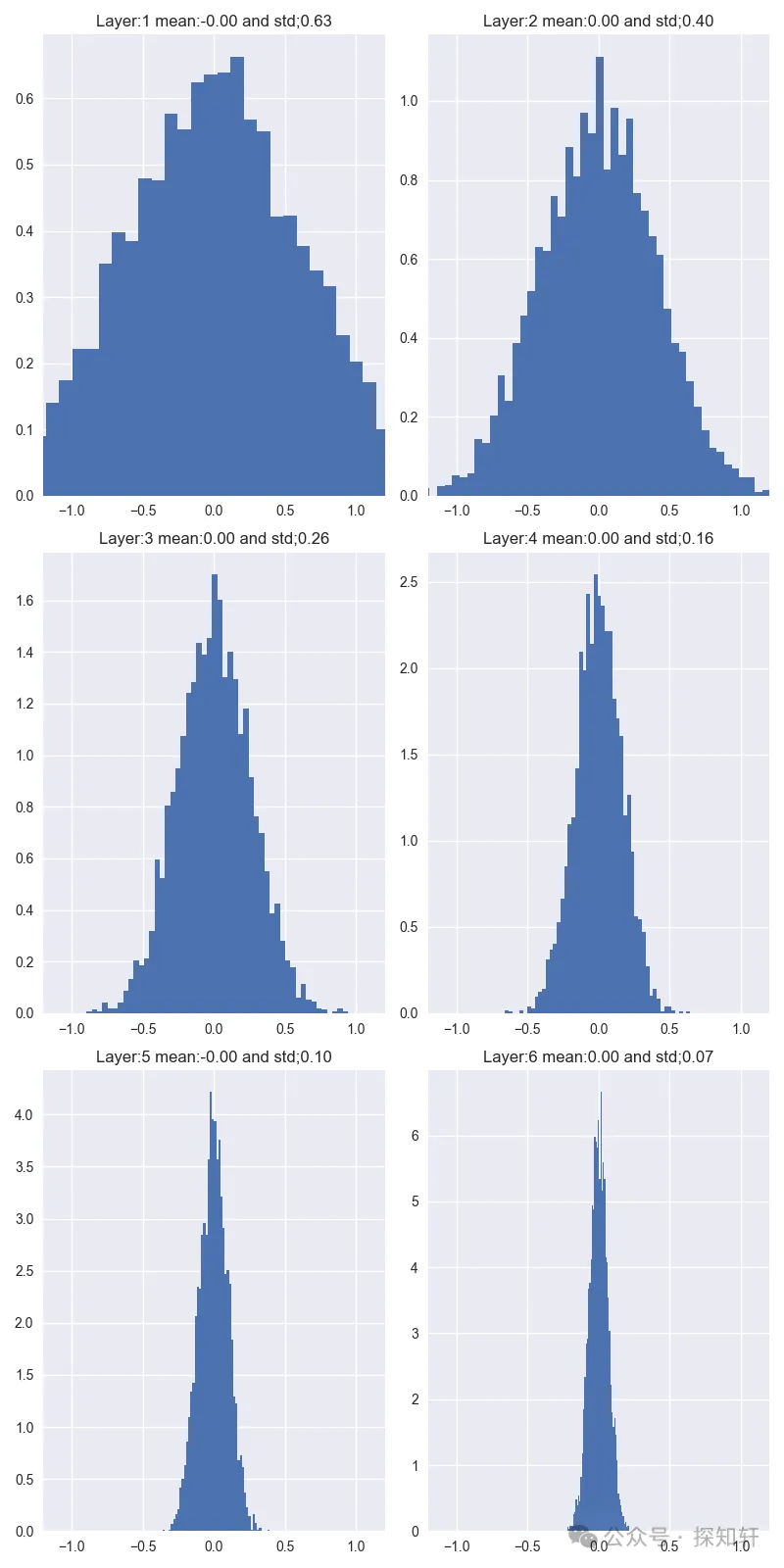
我们可以看到,在这种情况下,方差会增减减小,并且减小的速率很大,在第六层就快退化成方差等于0了。所以如果使用它初始化,会使得模型随着层数的增加参数退化成0,很难训练。
所以,我们在使用xavier或者Normal (std=0.02)来做qkv projection矩阵的初始化的时候,基本上能够保证方差在允许的范围内变化。
到这里,我们可以下一个粗浅的结论:transformer结构中线性层本身选择的初始化方法就是为了保证通过它的输入输出方差能够稳定,所以线性层变化并不会扩大输入信号的方差,也不是需要scale的根源所在。
下面我们进一步来详细分析softmax本身的特性。
softmax的特性: 大的更大,小的更小
对于一个序列,定义为
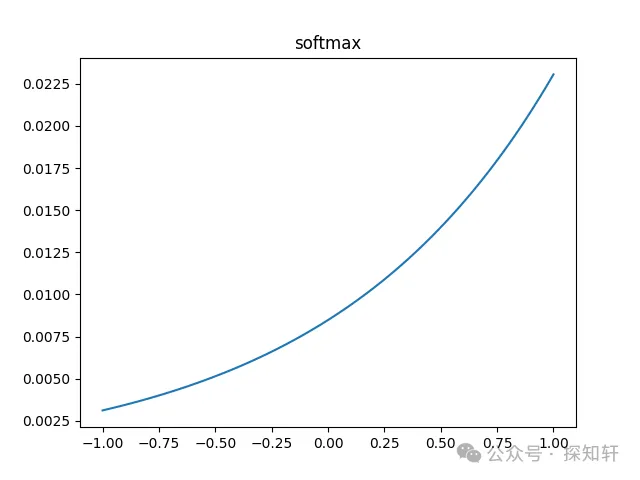
softmax其实是有拉大对比度的功能的,当一个序列里面有某个数比较大的时候,处理之后的结果接近于one-hot。

从上面的图里面我们可以清晰看到,当序列里面最大的数逐渐变大的时候(对应于均值和方差都在变大),哪怕其它的数量级也在跟着变大,最终结果也是类似one-hot编码,最大的数的位置的softmax值接近1,其它地方接近0。
这里我们其实回到了前言里面的图:
我们计算是为了要得到所有的权重系数来对进行加权求和,如果里面最大的数比较大,那么会退化成选择里面的某一行而不是所有的行进行加群求和。
到这里我们可以猜测要使用进行缩放有可能是整体的值都会比较大,需要使用它来消减均值和方差。为了证明这一点,我们继续详细分析的值的分布
值跟紧密相关
,我们计算softmax的时候是针对每个head单独计算的。对于第个attention head,,。其中为batch size,为sequence length,为num head,为size per head。
我们现在研究任意一个batch 中得到的,因为softmax是针对这个矩阵的每一行单独做的,我们来研究里面的某一行。为了方便,我们记,。假设我们现在研究的是第行,那么
对里面的第个数进行研究
由于是独立的,所以
其中等号在的分布均值为0的时候成立。
可以看到,softmx作用的每一个元素除了跟输入的方差相关之外,还跟线性相关。一般来说,都比较大。例如在Bert,GPT-2, GPT-3和T5这些模型中,。所以,我们非常有比较把这一项去掉,也就是说,我们想要把方差除以,这对应于把T中的每一项除以。
到这里,我们基本分析清楚了为什么要在softmax里面使用来对矩阵进行缩放。
实战分析
实验对比(基于GPT-2训练):
| 场景 | ||
|---|---|---|
| 无缩放 | ||
| 缩放 |
结论:不缩放直接导致训练不稳定和注意力失效!
结语
综上,。softmax中需要值方差尽量小,均值合理,这样出来的结果分布比较均匀。如果有一个值比较大(注意是比较大,而不是特别大),那softmax计算的结果就接近one-hot。要让整体值比较小,除了要尽量限制均值之外,还需要限制这些值的方差,否则哪怕均值为0,方差非常大也意味着序列里面某个值比较大。
我们使用Layernorm或者RMSNorm尽量限制每一层的方差,这对应于尽量限制了。在此基础上,我们还需要限制,而这个限制就体现在这个公式中的上面。
这里当然会有细心的读者会问:为什么不连也一起处理掉呢?
这其实是个好问题,也其实是QK-Norm要干的事情。我后面会专门写一篇文章来分析pre-norm, post-norm, qk-norm, deepnorm。
参考资料
[1]. Attention之旅--浅谈self attention和multi-head attention
[2]. Xavier: Understanding the difficulty of training deep feedforward neural networks
最后小提示
对这方面有兴趣深入研究的同学,可以联系我获取所有的代码; 欢迎大家留言继续讨论; 点击在看,让更多同学避坑。