一个可以识别一切物体的模型
我们经常在使用sam或者sam2打掩码之后,可能会遇到需要label的问题。这个时候,可能你需要自己再去训一个resnet或者是说再去通过训练一个别的模型,用监督学习的方法来完成自己的工作。
但是这样非常地费时费力。光是打label就会耗费大量时间了。
那么这几天,我发现了一个这个模型,它叫recognize anything,字面意思,就是说它可以识别任何物体。
https://arxiv.org/pdf/2306.03514
我们一起来看一看这项技术有什么用,怎么用,以及它的核心方法是什么吧。
我们首先来详细来说一说它都有什么用,能够被用在哪些地方。
一、有何价值
1、强大的图像标注能力
RAM 的主要作用就是实现强大的图像标注。它可以精准地识别出图像里各种各样的物体、场景、属性和动作,并给它们贴上合适的标签。
比如,一张热闹的公园照片,里面有嬉戏的孩子、盛开的花朵、郁郁葱葱的树木和长椅,RAM 能快速识别出这些元素,标注出 “公园”“孩子”“花朵”“树木”“长椅” 等标签,而且识别精度超高,标签覆盖范围也特别广。

这在实际应用中可太有用了,不管是大规模图像数据的分类整理,还是智能图像搜索,RAM 都能大显身手。
比如说,在一个拥有海量图片的数据库里,使用 RAM 就能快速给图片标注,方便用户根据标签搜索到自己想要的图片,大大提高了图像管理和检索的效率。
2、zero-shot的学习能力
RAM 拥有超强的零样本学习能力,这意味着即使它没见过某些特定类别的图像,也能凭借强大的模型架构和学习能力,准确地识别并标注出来。
就好比一个没见过袋鼠的人,通过学习各种动物的特征和描述,当看到袋鼠的图片时,也能猜出这是一种类似有袋动物的生物。RAM 也是如此,它通过从大规模的图像 - 文本对中学习丰富的语义信息,构建了一个强大的知识体系。
这样一来,在遇到新的、没见过的类别时,它能利用这些知识进行推理和判断,实现准确标注。
这种能力打破了传统模型需要大量标注数据才能学习特定类别标签的限制,极大地拓展了图像标注的应用范围。例如,在一些新兴的、数据稀缺的领域,或者遇到罕见的图像类别时,RAM 的零样本学习能力就能发挥巨大作用,让图像标注不再受限于数据不足的问题。
3、医疗领域,与SAM等其他模型结合
由于 RAM 强大的标注能力和零样本学习特性,它在众多领域都有广泛的应用前景。
在自动驾驶领域,车辆需要快速准确地识别道路上的各种物体,像行人、其他车辆、交通标志等。RAM 可以实时对车载摄像头拍摄的图像进行标注,帮助自动驾驶系统做出正确的决策,保障行车安全。
在医疗影像分析中,医生可以借助 RAM 对 X 光、CT 等影像进行标注,辅助诊断疾病,提高诊断效率和准确性。
在智能安防领域,监控摄像头拍摄的大量图像可以通过 RAM 进行实时标注,快速识别异常行为和目标物体,实现智能监控和预警。
而且,RAM 还能和其他模型(如 Grounding DINO 和 SAM)结合,形成一套更强大的视觉语义分析流程,进一步拓展其在不同领域的应用。
二、核心方法
那说完了它的核心价值,我们就来说说它的方法,也就是说它到底是通过什么样的方式来去实现这件事情的。
1、构建统一的标签系统
RAM 的第一步是打造一个超厉害的通用统一标签系统。这个标签系统可不是随便拼凑的,它融合了好多热门学术数据集(像分类、检测、分割相关的数据集)里的类别,还有商业标注产品(比如 Google、Microsoft、Apple 的标注)中的标签。
研究人员把所有公开的标签和文本里常见的标签合并在一起,经过筛选和整理,最终得到了一个包含 6449 个标签的系统。
下面这个是一个类似于云图的东西,展示了Tag的来源分布:
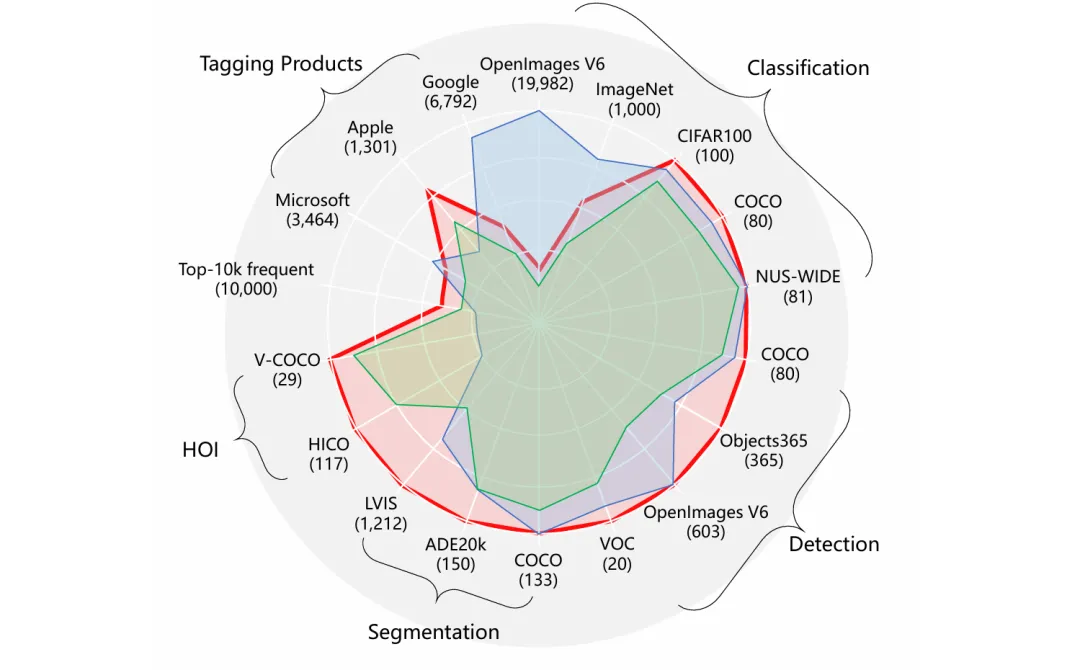
这个数量适中的标签系统能覆盖大部分常见的标签,而且每个标签都很有代表性。
比如说,在描述一张家庭聚会的照片时,标签系统里不仅有常见的 “人”“桌子”“食物”,还会包含像 “聚会”“欢笑” 这类能描述场景和氛围的标签。对于那些系统里没有的开放词汇标签,RAM 可以通过开放集识别技术来处理,进一步扩大了标签的覆盖范围,让模型能够应对各种复杂多样的图像标注需求。
2、利用大规模图像 - 文本对进行训练
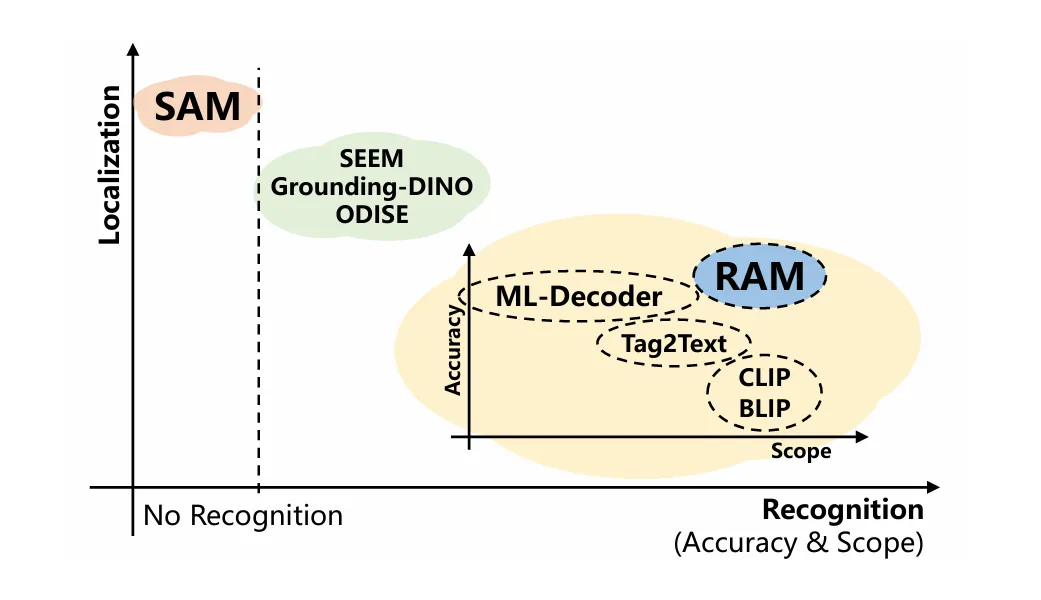
为了解决大规模高质量标注数据稀缺的问题,RAM 借鉴了 CLIP 和 ALIGN 的思路,利用公开的大规模图像 - 文本对来训练模型。
具体做法是,通过自动文本语义解析技术,从这些图像 - 文本对的文本中提取出图像标签。
打个比方,对于 “一只猫在沙发上睡觉” 这句话,经过解析就能得到 “猫”“沙发”“睡觉” 这些图像标签。这样,就可以在不需要大量人工标注的情况下,获得丰富多样的无标注图像标签。
而且,这些从大量文本中提取的标签包含了丰富的语义信息和上下文信息,有助于模型学习到更广泛、更准确的图像特征和标签关系。与传统的人工标注方式相比,这种方法不仅节省了大量的人力和时间成本,还能获取到更全面、更具多样性的标注数据,为训练强大的图像标注模型奠定了坚实的基础。
3、设计数据引擎优化标注质量
从网上收集的图像 - 文本对数据往往存在很多问题,比如标签缺失、错误等。为了提高标注质量,RAM 设计了一个智能的数据引擎。
这个数据引擎主要有两个方式:生成和清洗。
在生成方面,先训练一个基线模型,利用它的生成和标注能力,为原始的图像 - 文本对补充更多的标签和描述。
比如说,对于一张只有简单描述 “一只狗” 的图片,基线模型可能会补充出 “宠物”“玩耍”“草地” 等标签,让标注信息更加丰富。
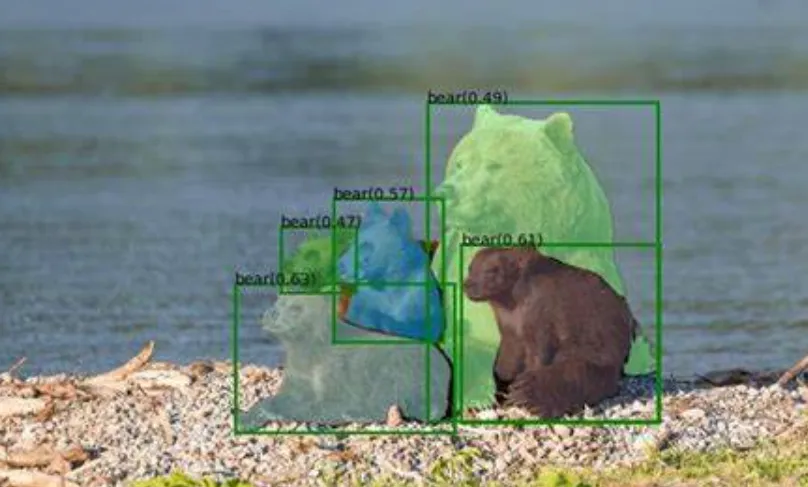
在清洗方面,首先使用 Grounding - Dino 模型来定位图像中特定类别的区域。然后用 K - Means++ 聚类算法对这些区域进行聚类分析,把那些偏离正常聚类的异常区域对应的标签去掉,同时去除基线模型预测不准确的标签。这样一来,经过数据引擎处理的数据更加准确、干净,大大提高了训练数据的质量,让模型在训练过程中能够学习到更可靠的图像 - 标签关系,从而提升标注性能。
Gounding - Dino检测效果示意:
4、独特的模型架构设计
RAM 的模型架构和 Tag2Text 有些相似,但又有自己独特的创新之处。
它主要由三个关键模块组成:图像编码器、图像 - 标签识别解码器和文本生成编码器 - 解码器。
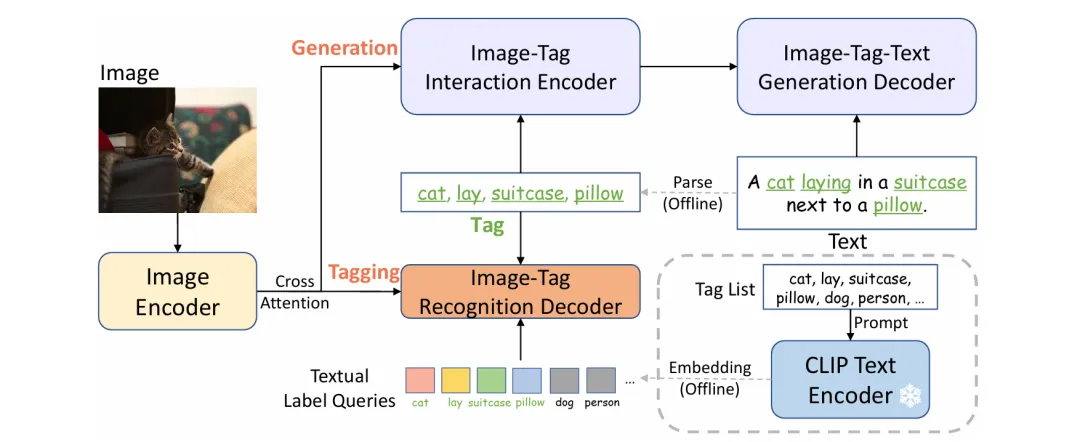
图像编码器负责提取图像的特征,就像是给图像做了一个 “特征画像”。图像 - 标签识别解码器用于根据图像特征预测标签,它通过交叉注意力层与图像特征进行交互,实现图像到标签的转换。
文本生成编码器 - 解码器则用于生成图像的描述文本,在训练过程中,它和图像 - 标签识别解码器联合训练,互相促进。和 Tag2Text 相比,RAM 的核心突破在于引入了开放词汇识别能力。
它利用现成的文本编码器,将标签列表中的单个标签编码成具有丰富语义上下文的文本标签查询。
这样,在训练阶段,即使遇到没见过的类别,模型也能通过这些语义丰富的查询进行推理和识别,大大增强了模型的泛化能力,让 RAM 能够识别任何常见的类别,而不仅仅局限于训练时见过的类别。