在几分钟内使用 Unsloth 对 Llama 3/deepseek 进行微调,用于医疗问题解答,并配合 QLoRA 快速推理
Unsloth对于单机微调模型非常高效, 能降低50%显存, 性能提升也非常明显. 另一片相关文章参见:
微调 DeepSeek-R1 进行股票交易及法律咨询应用(附代码)
关注公众号,拷贝并后台发送"unsloth微调代码",获取完整unsloth微调代码
用 Unsloth 对 Llama 3/deepseek 进微调

大型语言模型(LLMs)的内部知识是有限的。
当你在生产环境中使用它们时,你希望它们能够:
更新并基于于特定数据
以特定的方式返回相应
在不造成负面作用的同时提供帮助
不捏造信息, 避免幻觉
坚持它们的任务目标
这就是 微调 的用武之地,它涉及到进一步在特定数据集上训练 LLM,以内化关于领域、语调或预期任务目标的信息。
许多人可能会争辩说,RAG(检索辅助生成) 可以作为微调模型的替代方案,但这远非事实。
原因包括:
RAG 并不总是能有效地将模型植根于上下文中
RAG 不能改变你希望从 LLM 获得的特定风格、语调或输出格式
由于其检索步骤,RAG 还会增加响应延迟
但如何高效地微调呢?
微调一直以来都是计算密集型且耗时的,因为它传统上涉及通过在特定数据集上重新训练模型来更新所有模型权重。
对于拥有数十亿参数的大型LLMs来说,传统的微调涉及使用巨大且昂贵的GPUs,以及数小时甚至数天的训练时间来获得理想的结果。
2021年微软的一篇研究论文彻底改变了这一概念,他们介绍了一种参数高效的LLMs微调方式。
他们的方法,LoRA (低秩适应),与传统微调一个拥有175B参数的GPT-3相比,可训练参数数量减少了10000倍,GPU内存需求减少了3倍!
它通过冻结预训练模型权重,并在Transformer架构的每一层注入可训练的秩分解矩阵来实现这一点。
因此,与其更新数十亿个参数,使用LoRA,我们只需调整几百万个参数,就能达到与传统微调相近的准确度。
数学原理
在数学上,标准的微调涉及更新一个较大的权重矩阵 W,其维度为 d x k,其中 d 是模型的输入维度,k 是输出维度,如下所示:
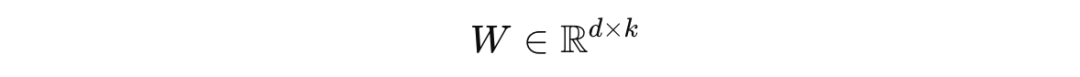
另一方面,LoRA 将对这个矩阵的改变分解为两个小得多的矩阵(较低秩)的乘积,如下所示:
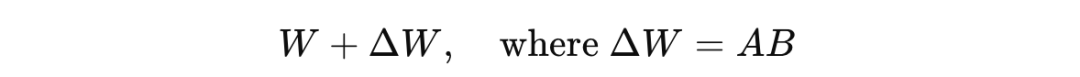
这些矩阵 A 和 B 被称为秩分解矩阵,它们的维度如下,其中 r 是矩阵的秩:
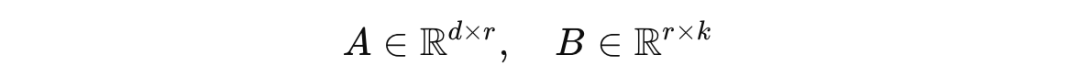
在微调过程中,只有这些矩阵会被训练,而原始的权重矩阵 W 保持不变。
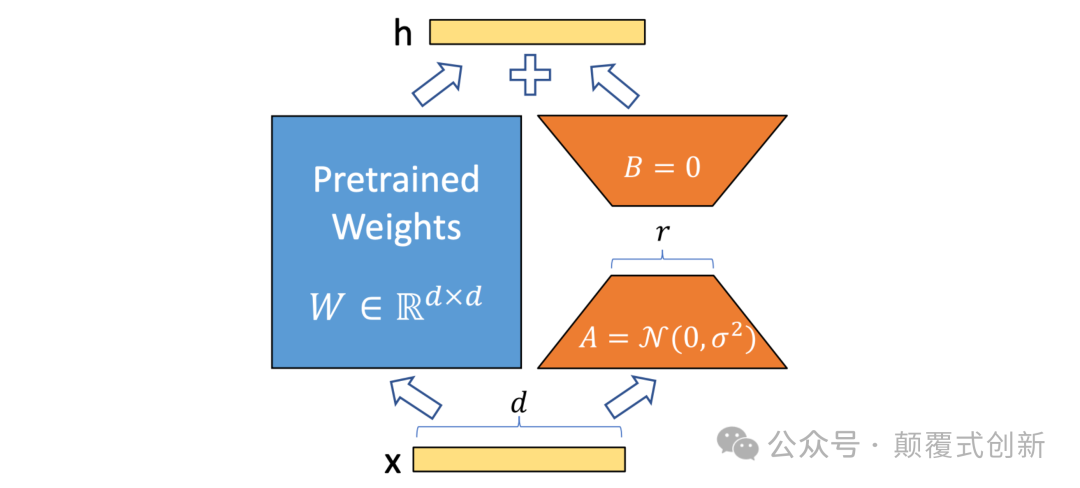
假设我们的大型语言模型(LLM)有以下值:
输入大小或
d=512输出大小或
k=2048
这导致了 1,048,576 个可学习的权重参数(512 x 2048)。
使用秩分解,r = 8 时,总的可学习权重参数将是 (d × r) + (r × k) = r × (d + k),这只有 20k 参数,而不是 100 万+。
这减少了大约 98% 的参数!
但我们能让LoRA运行得更快吗?
当然!这正是 Unsloth 所做的。
Unsloth 是一个框架,它结合了LoRA和4位量化技术,称为 QLoRA (Quantized Low-Rank Adaptation)。
如果你对 'Quantization' 这个术语不熟悉,这里是它的含义。
在深度学习中,默认的计算和模型参数精度是 32位浮点数 (FP32)。
这意味着每个参数在内存中占用32位。
在 4位量化 中,这些参数被减少到4位精度,这大大降低了内存需求和训练时间。
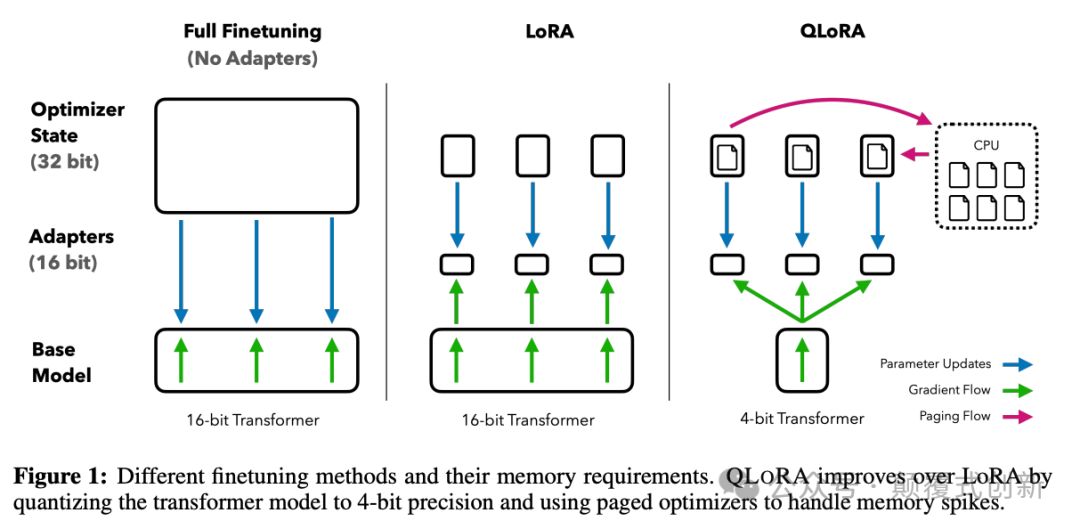
Unsloth 通过使用 Triton 手动推导反向传播步骤并将PyTorch模块重写为高效的GPU内核,进一步优化了QLoRA的默认实现。
这使得它在不牺牲准确性的情况下,相比传统方法,实现了高达 2.7倍的微调速度,并且减少了多达74%的内存使用。
现在我们已经了解了Unsloth的基础知识,让我们用它来微调一个LLM。
微调你的LLM以准确回答医学问题
在这节课中,我们的目标是微调 Llama-3.2–1B-Instruct 模型,让它能准确回答医学问题。
这个模型已经通过监督式微调(SFT)和结合人类反馈的强化学习(RLHF)进行了微调,以符合人类对帮助性和安全性的偏好。
我们将进一步训练它使用的数据集是 MedQA-USMLE,这是一个在 Hugging Face 上可用的开源数据集。
安装 Unsloth
Unsloth 只有在你有 NVIDIA GPU 的时候才能工作。
我们会使用 Google Colab 和 T4 GPU 运行时来解决这个问题。
我们按照下面的步骤安装 unsloth 包:
!pip install unsloth下载基础模型和分词器
我们来下载 4-bit 量化的 Llama-3.2–1B-Instruct 及其分词器。
from unsloth import FastLanguageModelmodel, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Llama-3.2-1B-Instruct", max_seq_length = 2048, load_in_4bit = True,)使用医学问题进行测试
我们来给基础模型提一个测试问题。
# 使用医学问题进行测试import torchdevice = "cuda" if torch.cuda.is_available() else "cpu"tokenizer.pad_token = tokenizer.eos_tokenmodel.eval()prompt = """Q. 一位23岁的孕妇怀孕22周,出现排尿时的灼烧感。她说这种情况从1天前开始,并且尽管多喝水和服用蔓越莓提取物,症状还是在恶化。除此之外她感觉还好,并且有医生跟踪她的怀孕情况。她的体温是97.7°F(36.5°C),血压是122/77 mmHg,脉搏是80/分钟,呼吸是19/分钟,室内空气中的氧饱和度是98%。体格检查值得注意的是没有肋脊角压痛和一个妊娠子宫。以下哪项是治疗这位患者的最佳选择?选项:A: 氨苄西林B: 头孢曲松C: 环丙沙星D: 多西环素E: 硝基呋喃请选择正确答案。"""inputs = tokenizer(prompt, return_tensors="pt").to(device)input_len = inputs["input_ids"].shape[-1]output = model.generate(**inputs, max_new_tokens=128)response = tokenizer.decode(output[0][input_len:], skip_special_tokens=True)print("测试提示:\n", prompt.strip())print("\n测试回应:\n", response.strip())
以下是我们得到的回应。
测试提示: Q. 一位23岁的孕妇怀孕22周,出现排尿时的灼烧感。她说这种情况从1天前开始,并且尽管多喝水和服用蔓越莓提取物,症状还是在恶化。除此之外她感觉还好,并且有医生跟踪她的怀孕情况。她的体温是97.7°F(36.5°C),血压是122/77 mmHg,脉搏是80/分钟,呼吸是19/分钟,室内空气中的氧饱和度是98%。体格检查值得注意的是没有肋脊角压痛和一个妊娠子宫。以下哪项是治疗这位患者的最佳选择?选项:A: 氨苄西林B: 头孢曲松C: 环丙沙星D: 多西环素E: 硝基呋喃测试回应: F: 左氧氟沙星G: 多西环素H: 甲硝唑I: 甲氧苄啶/磺胺甲噁唑J: 阿奇霉素A. 头孢曲松B. 头孢曲松C. 环丙沙星D. 多西环素E. 硝基呋喃F. 左氧氟沙星G. 多西环素H. 甲硝唑I. 甲氧苄啶/磺胺甲噁唑J. 阿奇霉素最好的模型回答出现了幻觉般的新选项,并没有回答我们的问题。哎呀,这需要修复!
### 加载和准备医学问答数据集[MedQA-USMLE](https://huggingface.co/datasets/Neelectric/MedQA-USMLE/viewer/default/train?row=57) 数据集包含了来自[美国医学执照考试(USMLE)](https://www.usmle.org/)的10,178个训练问题。我们按如下方式加载它:```python```markdown# 加载数据集from datasets import load_datasetdataset = load_dataset("Neelectric/MedQA-USMLE", split="train")这个数据集包含以下几列。
Dataset({ features: ['question', 'answer', 'options', 'meta_info', 'answer_idx'], num_rows: 10178})下面是一个训练样例的样子。
print("问题:\n", dataset[0]["question"])print("\n选项:\n", dataset[0]["options"])print("\n答案:\n", dataset[0]["answer"])问题:一位23岁的孕妇怀孕22周,出现排尿时的灼烧感。她说这种感觉从1天前开始,并且尽管多喝水和服用蔓越莓提取物,症状还是在恶化。除此之外她感觉良好,并且有医生跟踪她的孕期。她的体温是97.7°F(36.5°C),血压是122/77 mmHg,脉搏是80/分钟,呼吸是19/分钟,室内空气中的氧饱和度是98%。体格检查显著的是没有肋脊角压痛和一个妊娠子宫。以下哪项是治疗这位患者的最佳选择?选项:{'A': '氨苄西林', 'B': '头孢曲松', 'C': '环丙沙星', 'D': '多西环素', 'E': '呋喃妥因'}答案:呋喃妥因我们需要将这个数据集转换成聊天风格的提示与回应结构,并按照我们的模型内部期望的格式进行格式化,以便进行微调。
具体操作如下。
def format_prompts(examples): questions = examples["question"] options_list = examples["options"] answers = examples["answer"] conversations = [] for q, opts, ans in zip(questions, options_list, answers): options_text = "\n".join([f"{key}. {val}" for key, val in opts.items()]) prompt = f"{q}\n\n选项:\n{options_text}\n\n请选择正确答案。" response = f"正确答案是{ans}。" conversations.append([ {"role": "user", "content": prompt}, {"role": "assistant", "content": response}, ]) texts = [tokenizer.apply_chat_template(convo, tokenize=False, add_generation_prompt=False) for convo in conversations] return {"text": texts}dataset = dataset.map(format_prompts, batched=True)现在我们的数据集新增了一个'text'列,样子如下。
Dataset({ features: ['question', 'answer', 'options', 'meta_info', 'answer_idx', 'text'], num_rows: 10178})这个数据集中的一个例子如下所示。
print("问题:\n", dataset[0]["question"])print("\n选项:\n", dataset[0]["options"])print("\n答案:\n", dataset[0]["answer"])print("\n格式化文本:\n", dataset[0]["text"])问题:一位23岁的孕妇怀孕22周,出现排尿时的灼烧感。她说这种感觉从1天前开始,并且尽管多喝水和服用蔓越莓提取物,症状还是在恶化。除此之外她感觉良好,并且有医生跟踪她的孕期。她的体温是97.7°F(36.5°C),血压是122/77 mmHg,脉搏是80/分钟,呼吸是19/分钟,室内空气中的氧饱和度是98%。体格检查显著的是没有肋脊角压痛和一个妊娠子宫。以下哪项是治疗这位患者的最佳选择?选项:A. 氨苄西林B. 头孢曲松C. 环丙沙星D. 多西环素E. 呋喃妥因请选择正确答案。<|eot_id|><|start_header_id|>assistant<|end_header_id|>正确答案是呋喃妥因。<|eot_id|>配置模型进行参数高效微调(PEFT)/ LoRA
让我们准备好模型进行微调。
model = FastLanguageModel.get_peft_model( model, r=16, target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], lora_alpha=16, lora_dropout=0, bias="none", use_gradient_checkpointing="unsloth", random_state=42, use_rslora=False, loftq_config=None,)这些参数各代表以下含义:
model:我们打算微调的大型语言模型(LLM)r:低秩适应(LoRA)更新矩阵的秩target_modules:我们用LoRA针对的模型层。在我们的案例中,我们使用的是与LLM的变换器模型中的注意力和前馈机制相关联的层。lora_alpha:微调过程中LoRA更新的缩放因子lora_dropout:LoRA的丢弃率bias:设置微调期间是否更新偏置项use_gradient_checkpointing:使用梯度检查点来减少VRAM的使用。在我们的案例中,我们使用的是Unsloth设计的自定义实现。random_state:使用LoRA时用于随机性的种子use_rslora:设置微调期间是否使用稳定秩的LoRA(RS-LoRA)loftq_config:如果我们使用的话,设置LoftQ(LoRA微调感知量化)的参数
设置训练器
在这一步,我们按照下面的方式设置了 Huggingface TRL 的 SFTTrainer:
from trl import SFTTrainertrainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = dataset, dataset_text_field = "text", max_seq_length = 2048, dataset_num_proc = 2, packing = False, args=TrainingArguments( per_device_train_batch_size = 2, gradient_accumulation_steps = 4, warmup_steps = 5, max_steps = 200, learning_rate = 2e-4, logging_steps = 10, optim = "adamw_8bit", weight_decay = 0.01, lr_scheduler_type = "linear", seed = 700, output_dir = "outputs", report_to = "none", ),)这个类中有一些我们之前没见过的参数,它们的含义如下:
train_dataset:用于训练的数据集dataset_text_field:数据集中包含用于训练文本的字段max_seq_length:输入数据的最大序列长度。超过这个长度的序列将被截断。dataset_num_proc:用于数据预处理的进程数packing=False:防止多个示例被串联成一个单一序列args=TrainingArguments(...):如下所示的训练参数配置per_device_train_batch_size:每个设备每批训练样本的数量。gradient_accumulation_steps:在执行优化步骤之前累积梯度的步数warmup_steps:训练开始时学习率线性预热的步数max_steps:训练的总步数learning_rate:优化器的学习率。logging_steps:记录训练步数的频率optim:指定要使用的优化器weight_decay:为了防止过拟合而设置的权重衰减系数lr_scheduler_type:学习率调度器的类型在我们的案例中,linear在训练期间线性减少学习率。output_dir:模型检查点和训练输出将被保存的目录。report_to:指定报告平台(例如 Tensorboard)
接下来,我们确保在微调期间,损失是根据 assistant 的回应来计算的,而不是对话中的 system 和 user 部分。
from unsloth.chat_templates import train_on_responses_onlytrainer = train_on_responses_only( trainer, instruction_part="<|start_header_id|>user<|end_header_id|>\n\n", response_part="<|start_header_id|>assistant<|end_header_id|>\n\n",)检查内存统计信息
在我们开始微调之前,让我们先了解一下我们的 GPU 的一些细节。
import torchgpu_stats = torch.cuda.get_device_properties(0)start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")print(f"{start_gpu_memory} GB of memory reserved.")GPU = Tesla T4. Max memory = 14.741 GB.4.252 GB of memory reserved.开始训练
最后,我们按照下面的方式开始我们的训练。
trainer_stats = trainer.train()一旦完成,我们可以按照下面的方式保存我们的模型和分词器。
Output:# 保存 LoRA 微调后的模型和分词器output_dir = "medqa_finetuned_model"model.save_pretrained(output_dir)tokenizer.save_pretrained(output_dir)检查内存和时间统计
下面的代码将给我们提供所有内存和训练时间的统计信息,我们可以用这些信息来优化我们后续的微调实验。
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)used_memory_for_lora = round(used_memory - start_gpu_memory, 3)used_percentage = round(used_memory / max_memory * 100, 3)lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)print(f"{trainer_stats.metrics['train_runtime']} 秒用于训练。")print( f"{round(trainer_stats.metrics['train_runtime']/60, 2)} 分钟用于训练。")print(f"峰值保留内存 = {used_memory} GB。")print(f"训练的峰值保留内存 = {used_memory_for_lora} GB。")print(f"峰值保留内存占最大内存的百分比 = {used_percentage} %。")print(f"训练的峰值保留内存占最大内存的百分比 = {lora_percentage} %。")259.3875 秒用于训练。4.32 分钟用于训练。峰值保留内存 = 4.252 GB。训练的峰值保留内存 = 0.0 GB。峰值保留内存占最大内存的百分比 = 28.845 %。训练的峰值保留内存占最大内存的百分比 = 0.0 %。注意微调这个巨大模型只用了几分钟时间!
推理
最后,我们要测试一下基础模型和微调后的模型在医学问题上的表现。
我们首先要设置这些模型,并将它们置于评估模式。
base_model_name = "unsloth/Llama-3.2-1B-Instruct"lora_path = "medqa_finetuned_model"max_seq_length = 2048加载基础模型
base_model, tokenizer = FastLanguageModel.from_pretrained(model_name = base_model_name,max_seq_length = max_seq_length,dtype = torch.float16,load_in_4bit = True,)
tokenizer.pad_token = tokenizer.eos_tokentokenizer = get_chat_template(tokenizer, chat_template="llama-3.2")
base_model.eval()
# 加载 LoRA 微调模型lora_model, _ = FastLanguageModel.from_pretrained( model_name = base_model_name, max_seq_length = max_seq_length, dtype = torch.float16, load_in_4bit = True,)lora_model.load_adapter(lora_path)lora_model.eval()接下来,我们编写并使用一个函数来检查和比较这些模型的响应。
在下面的案例中,我们将使用训练数据集中的一个例子,但为了更好地评估微调模型,你理想情况下会使用不同的定量(像 BLEU、Perplexity 等指标)和定性(人类专家审查/ LLM-as-a-judge)方法。
def compare_model_outputs(base_model, lora_model, tokenizer, prompt, max_new_tokens=128): def generate_response(model, prompt): formatted_prompt = tokenizer.apply_chat_template( [{"role": "user", "content": prompt.strip()}], tokenize=False, add_generation_prompt=True, ) inputs = tokenizer(formatted_prompt, return_tensors="pt").to(device) input_len = inputs["input_ids"].shape[-1] output = model.generate(**inputs, max_new_tokens=max_new_tokens) response = tokenizer.decode(output[0][input_len:], skip_special_tokens=True) return response.strip() print("Prompt:\n") print(prompt.strip()) print("\nBase Model Response:\n") print(generate_response(base_model, prompt)) print("\nFine-Tuned Model Response:\n") print(generate_response(lora_model, prompt))prompt = """Q. 一位23岁的孕妇怀孕22周,出现排尿时烧灼感。她说这种情况从1天前开始,并且尽管多喝水和服用蔓越莓提取物,症状仍在恶化。除此之外她感觉良好,并由医生跟踪她的怀孕情况。她的体温是97.7°F(36.5°C),血压是122/77 mmHg,脉搏是80/分钟,呼吸是19/分钟,室内空气中的氧饱和度是98%。体格检查值得注意的是没有肋脊角压痛和一个妊娠子宫。以下哪项是治疗这位患者的最佳选择?选项:A:氨苄西林B:头孢曲松C:环丙沙星D:多西环素E:呋喃妥因请选择正确答案。"""compare_model_outputs(base_model, lora_model, tokenizer, prompt)这返回了以下响应。
Prompt:Q. 一位23岁的孕妇怀孕22周,出现排尿时烧灼感。她说这种情况从1天前开始,并且尽管多喝水和服用蔓越莓提取物,症状仍在恶化。除此之外她感觉良好,并由医生跟踪她的怀孕情况。她的体温是97.7°F(36.5°C),血压是122/77 mmHg,脉搏是80/分钟,呼吸是19/分钟,室内空气中的氧饱和度是98%。体格检查值得注意的是没有肋脊角压痛和一个妊娠子宫。以下哪项是治疗这位患者的最佳选择?选项:A:氨苄西林B:头孢曲松C:环丙沙星D:多西环素E:呋喃妥因请选择正确答案。Base Model Response:为了确定这位患者的最佳治疗方案,让我们分析提供的信息:1. **症状**:患者排尿时出现烧灼感,从1天前开始,尽管多喝水和服用蔓越莓提取物,症状仍在恶化。这表明是尿路感染(UTI)。2. **年龄和怀孕**:患者23岁,怀孕22周。虽然怀孕期间使用抗生素没有直接禁忌,但由于潜在风险,不建议在怀孕期间使用蔓越莓提取物。3. **生命体征**:患者体温正常,血压是Fine-Tuned Model Response:正确答案是呋喃妥因。这个答案是正确的,也没有基础模型响应那么啰嗦。
恭喜!我们已经成功地微调了一个 LLM,使其在相关医学信息上有依据,并且能够以对话风格进行响应。```
如何最佳地微调一个LLM?
微调更多的是试错过程,而不是遵循确切的指导原则,但这里有一些通用原则可以帮助你达到更好的微调性能。
包含干净、多样、高质量例子的数据集会带来更好的性能。
人工制作的数据集比合成生成的数据集能带来更好的性能。
参数数量更多的模型会表现得更好,但微调的速度会更慢。
短时间内的微调可能不够充分,但如果做得过度,可能会导致灾难性遗忘,模型在之前学到的信息上的性能会急剧下降。
全面微调可能会带来比参数高效微调更好的结果,但它会占用更多的资源和时间。
模型评估可以从人工评估(对于用例来说可能更可靠,但可能既昂贵又耗时)到使用LLM评估器(可能成本效益高且快速,但由于LLM的偏见可能不太可靠)
最后,仔细阅读文档,试验超参数,进行大量实验是获得微调成功的关键。
关注公众号,拷贝并后台发送"unsloth微调代码",获取完整unsloth微调代码