大模型入门指南 - CheckPoint(检查点):小白也能看懂的“训练存档”全解析
刚接触大模型论文时,看到满屏的“CheckPoint”是不是瞬间头大?别慌!其实它就像游戏里的自动存档——关键时刻能救你“命”,还能让模型“越练越聪明”。今天用最通俗的话,带你拆解CheckPoint(检查点)如何实现模型“训练存档”。
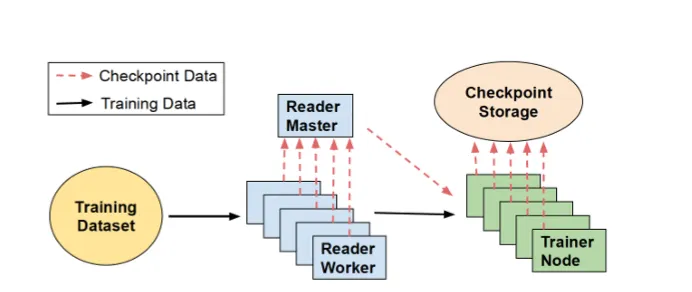
一、概念解读
模型参数(脑子里的知识:权重、偏置) 训练进度(经验值:训练轮数(epoch)、批次编号(batch)) 模型超参数(辅助工具:优化器状态、学习率)
二、技术实现
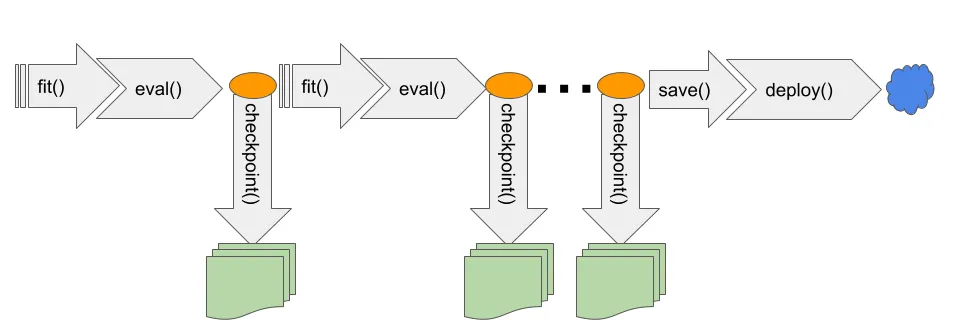
- 拍照存档:
大模型:“主人,我刚学了1000个单词,现在记性里是酱紫的……” 开发者:“好的,拍照存档!”(代码自动保存权重、优化器状态到文件) - 读档恢复:
大模型:“主人,我好像失忆了……” 开发者:“别慌,看这张照片!”(加载CheckPoint文件,大模型瞬间恢复记忆)
PyTorch如何实现CheckPoint(检查点)?PyTorch使用torch.save和torch.load手动保存/加载模型状态字典(state_dict)。
checkpoint_epoch1_loss0.5.pth)。模型权重(Weights):大模型的“大脑神经元连接强度”(如1000个单词对应的词向量矩阵) 优化器状态(Optimizer):大模型的“学习方法”(如Adam优化器的动量、学习率衰减记录) 训练元数据(Metadata):大模型的“进度条”(当前轮次、batch步数、损失值)

import torchimport os# 定义模型和优化器model = Model()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练循环best_loss = float('inf') # 记录最佳损失值for epoch in range(100):model.train()total_loss = 0.0# 模拟训练步骤for batch in dataloader:inputs, labels = batchoptimizer.zero_grad()outputs = model(inputs)loss = torch.nn.functional.cross_entropy(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()avg_loss = total_loss / len(dataloader)# 保存条件判断(轮数或损失值)save_flag = Falseif (epoch + 1) % 10 == 0: # 每10轮保存一次save_flag = Trueelif avg_loss <= 0.5: # 损失≤0.5时保存save_flag = Trueif save_flag:checkpoint = {'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'loss': avg_loss}save_path = f"checkpoint_epoch{epoch+1}_loss{avg_loss:.2f}.pth"torch.save(checkpoint, save_path)print(f"Checkpoint saved: {save_path}")