你是否困惑:为何AI既能和你聊哲学、写科幻,但面对财报里“伪装”成正常数据的债务危机,或是法律条款间环环相扣的侵权陷阱时,却像“博而不精”的优等生,答案总差半步精准?这就像一位“通才学霸”虽然知识面广,但遇到具体学科难题时也需要“补课”——而模型微调(Fine-tuning)就是给AI“精准补课”的技术。
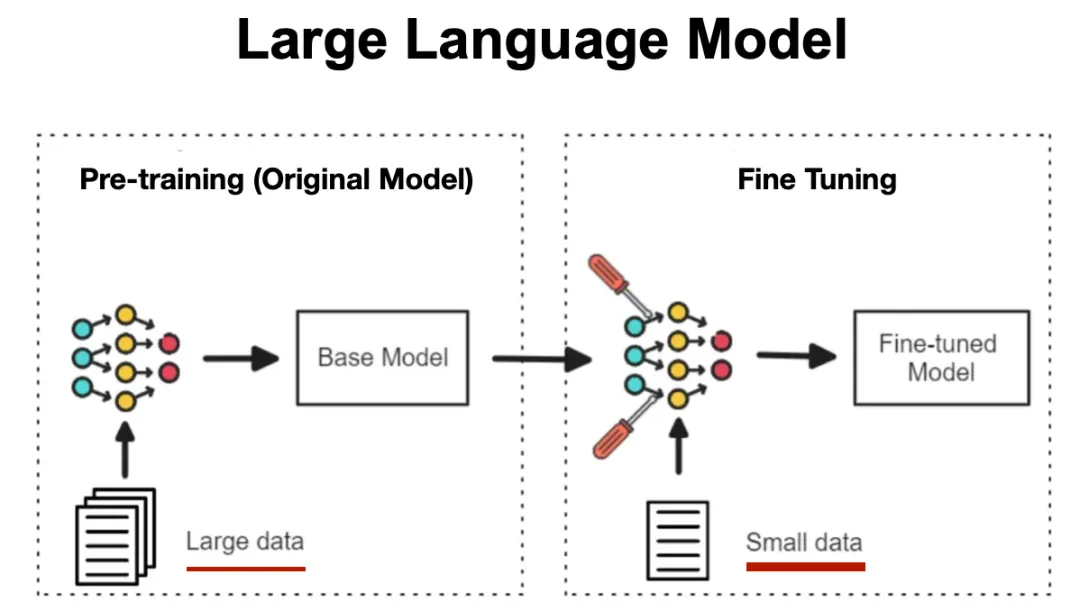
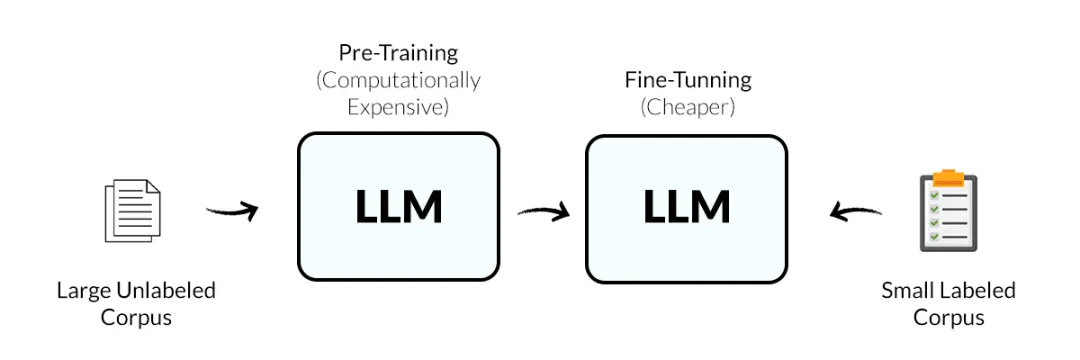
Fine-tuning(模型微调)到底是个啥?模型微调是在预训练大模型(如DeepSeek、LLaMA、Qwen等)的基础上,用特定领域或任务的数据集对模型参数进行二次训练,让大模型“从通才成为专家”。- 预训练模型:已在大规模无标注数据上学习通用特征(如语言规则、物体识别)。
- 微调:注入领域专属知识(如医疗术语、金融逻辑),使模型具备特定场景下的专业能力。
模型微调的本质是通过参数优化、数据适配与领域约束,将通用大模型的能力“聚焦”到特定场景,使其在保持基础能力的同时,精准适配行业需求。大模型预训练时学习了全网海量数据(如满血版DeepSeek的6710亿参数),但这些知识是“泛化”的,微调通过调整部分参数(如1%-10%的参数),让模型在保留基础能力的同时,强化对领域数据的敏感度。
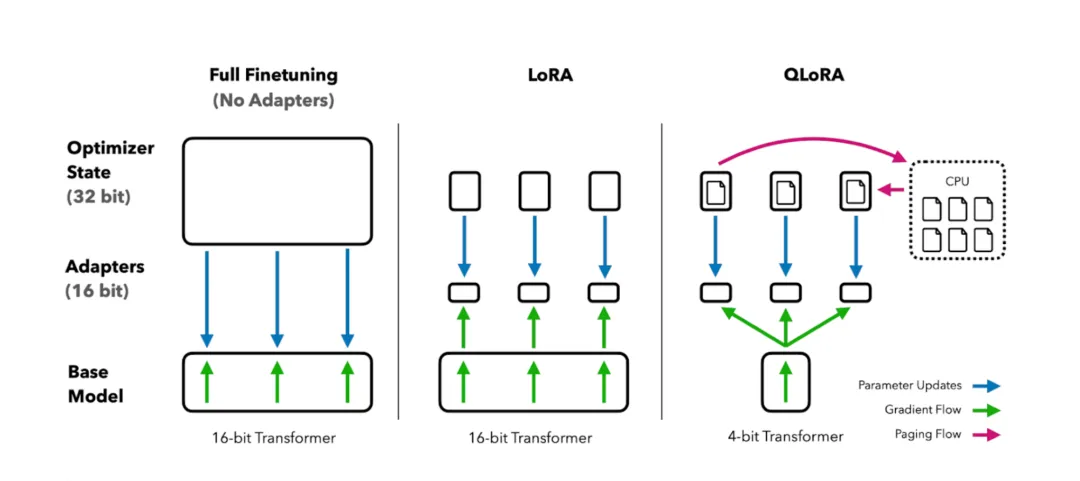
微调需使用领域专属数据(如法律需判例库),而非通用文本。数据需“小而精”,而非“大而杂”。例如,1000条标注的法律案例数据,可能比100万条通用文本更有效。通用模型可能生成“看似合理但错误”的答案(如法律条款引用错误)。微调通过损失函数设计(如增加法律条款一致性约束),让模型输出更符合领域逻辑(如引用《民法典》第X条)。为什么需要Fine-tuning(模型微调)?通用模型难以适配细分场景的专业需求,而微调能以极少量领域数据(1000+标注)和超低计算成本(节省90%+资源),快速定制出高精度、可落地的行业专家模型。通过合理选择数据策略和微调方法,即使新手也能在1周内完成首个定制化模型。随着QLoRA等PEFT技术的发展,微调门槛持续降低。最新数据显示,80%的企业级AI应用已采用微调方案。