大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析
大模型(如DeepSeek、Qwen等)参数规模动辄数百亿,全精度(FP32)存储和推理会占用大量显存且速度慢。而模型量化技术通过将浮点数压缩为低精度整数,不仅能让大模型“瘦身”至1/4甚至更小体积,还能显著提升推理效率。例如,175B参数的模型用FP32需700GB显存,而量化到INT4仅需约10GB。
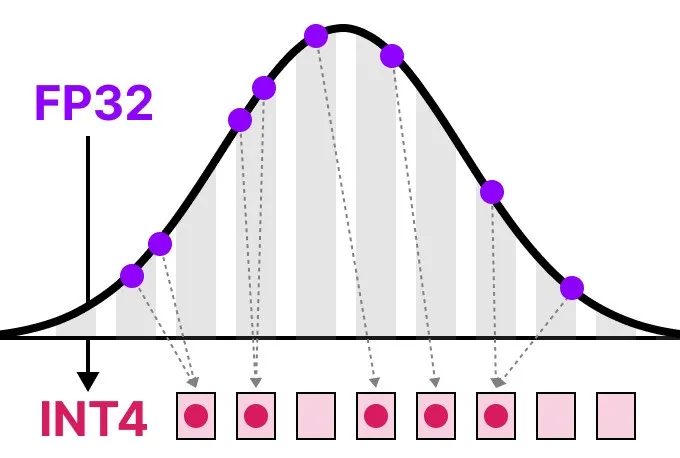
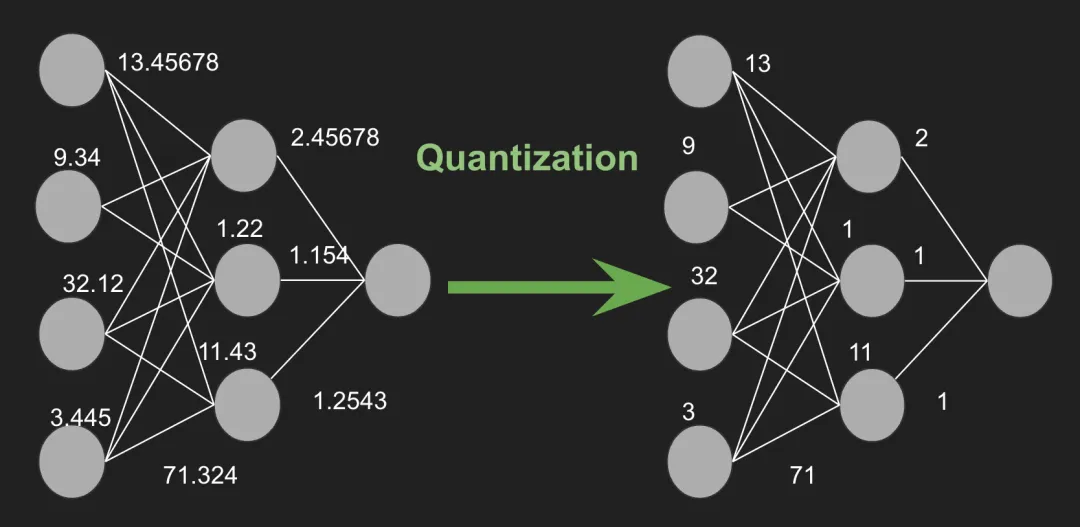
一、概念解读
FP32(浮点数):如同用科学计算器处理小数运算,精度高但计算慢、耗电多。 INT8(整数):如同用算盘处理整数运算,速度快、能耗低,但需通过“单位换算”保证结果接近。
min=-1.2, max=0.8;激活值范围:min=0.1, max=5.6。scale = (max - min) / (2^n - 1)(n为量化位数,如 INT8 时 n=8,2^8-1=255)zero_point = round(-min / scale)(确保浮点数 0 映射到整数 0,避免负数溢出)min=-1.2, max=0.8,INT8 量化:scale = (0.8 - (-1.2)) / 255≈0.00784,zero_point = round(-(-1.2) / 0.00784) ≈ 153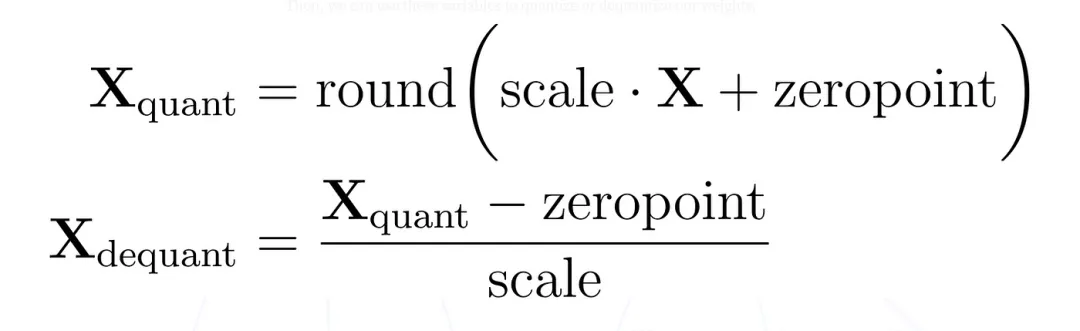
q = round(x / scale) + zero_point(将浮点数 x 映射为整数 q)x' = (q - zero_point) * scale(将整数 q 还原为浮点数 x')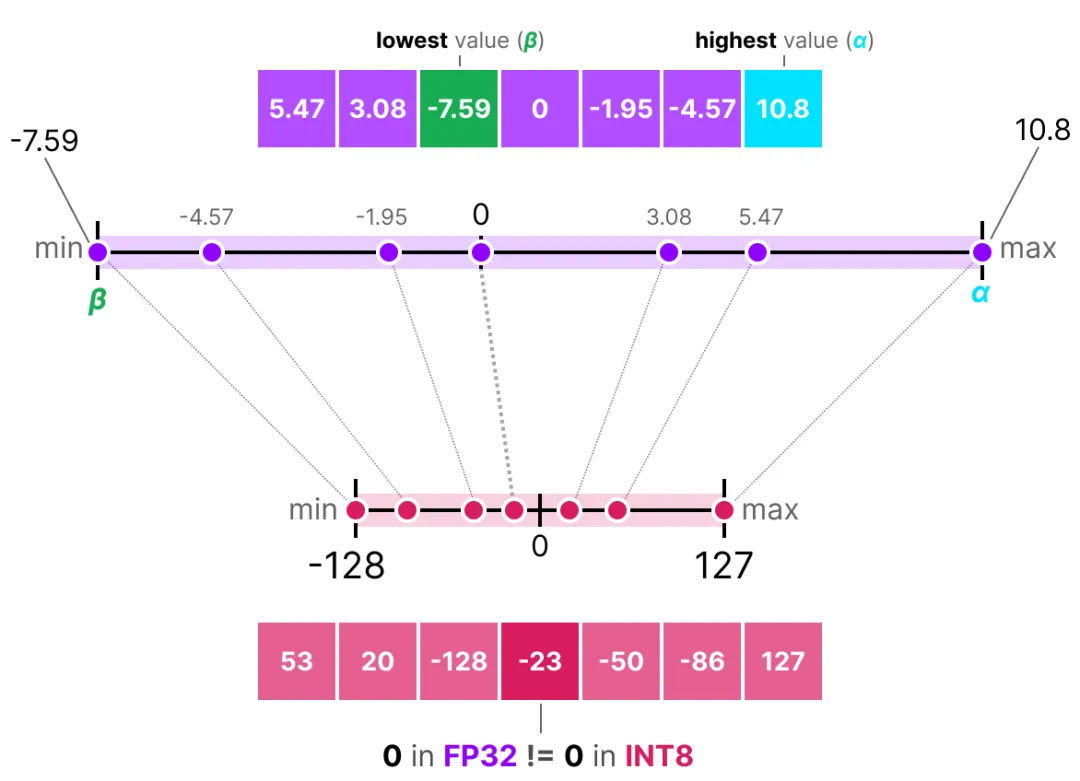
存储维度: INT8压缩4倍,INT4压缩8倍,实现“大象变蚂蚁”;带宽维度:内存访问量减少75%,推理速度提升2-4倍,打通“高速专线”。
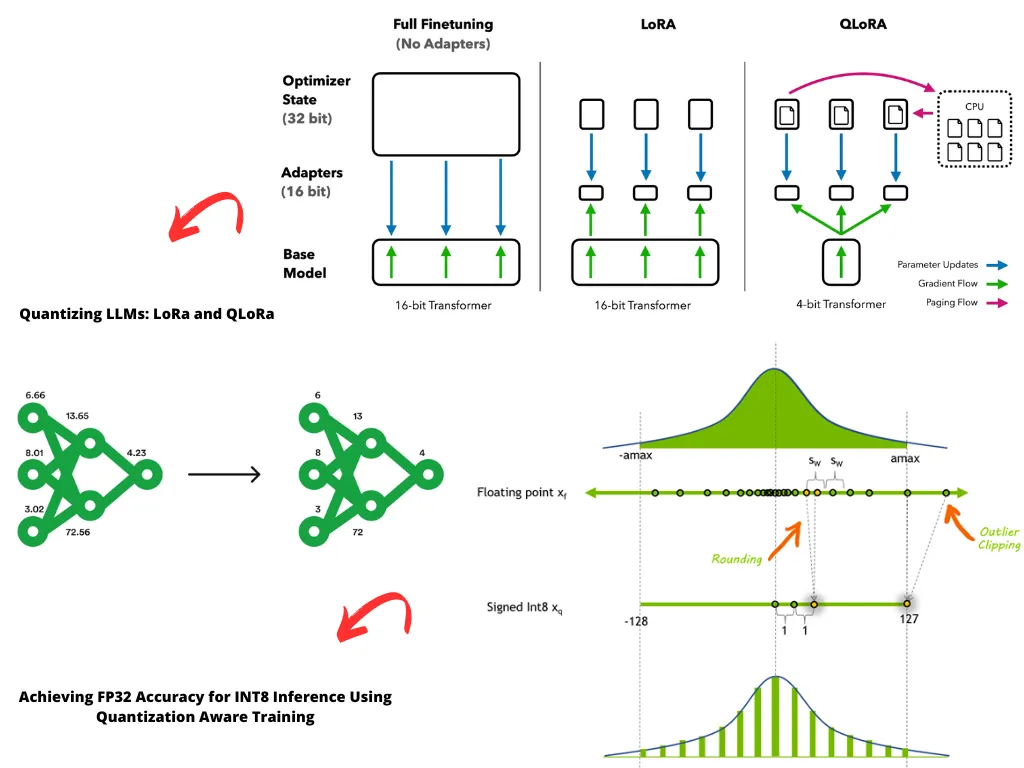
二、技术实现
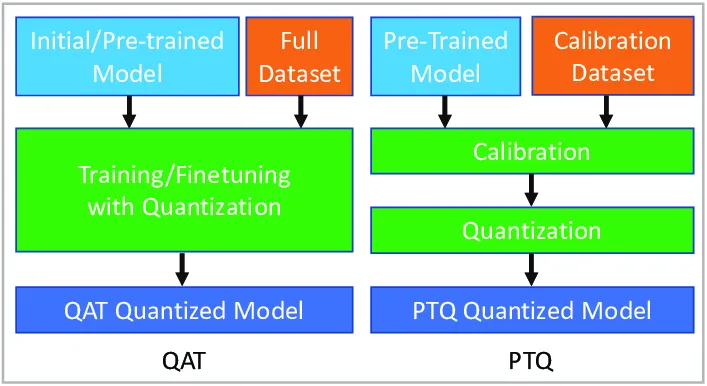
import torchfrom torch.quantization import quantize_dynamic# 加载预训练模型model = torch.load('model.pth')model.eval()# 动态量化(量化Linear和LSTM层)quantized_model = quantize_dynamic(model,{torch.nn.Linear, torch.nn.LSTM}, # 指定量化层类型dtype=torch.qint8)
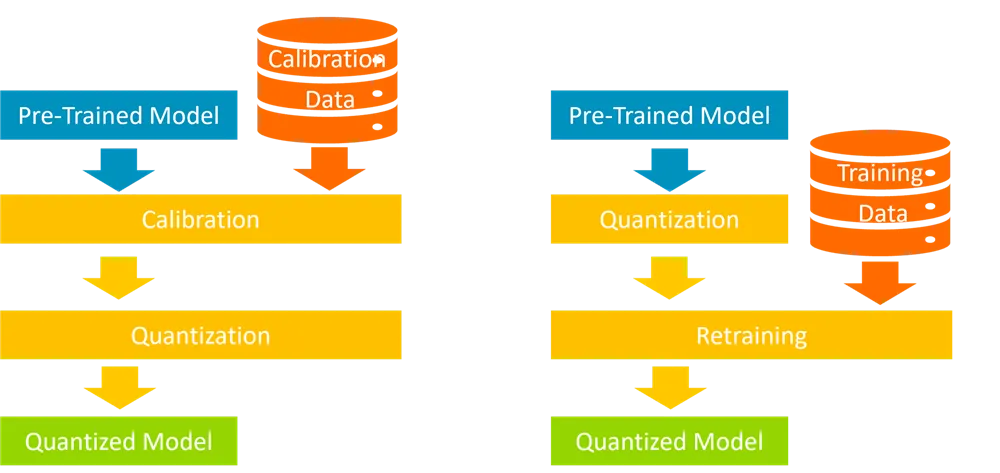
from torch.quantization import prepare, convert# 准备校准数据集def calibrate(model, data_loader):model.eval()with torch.no_grad():for inputs in data_loader:model(inputs)# 配置量化参数model.qconfig = torch.quantization.get_default_qconfig('fbgemm')model_prepared = prepare(model) # 插入Observer节点calibrate(model_prepared, data_loader) # 校准激活值范围quantized_model = convert(model_prepared) # 转换为量化模型
from torch.quantization import prepare_qat, FakeQuantize# 定义QAT模型model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')model_prepared = prepare_qat(model) # 插入伪量化节点# 训练阶段(模拟量化误差)optimizer = torch.optim.SGD(model_prepared.parameters(), lr=0.01)for inputs, labels in train_loader:outputs = model_prepared(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 转换至最终量化模型quantized_model = convert(model_prepared)