超越OCR!LLM时代最聪明的文档解析工具:从文档大纲到布局,从图表公式到图像理解,RAG效果翻倍!
训练LLM大语言模型90%的时间都耗在数据清洗上?复杂文档解析真有那么难?今天我们系统的聊下复杂文档解析的常见问题。
最近在GitHub发现了一款号称"多模态文档解析终结者"的工具。我们对比了Marker、MinerU、olmOCR、Surya、GOT-OCR 2.0、Mistral OCR等十几个开源/闭源模型,这可能是目前支持格式最全、上手最简单的大模型文档解析工具。
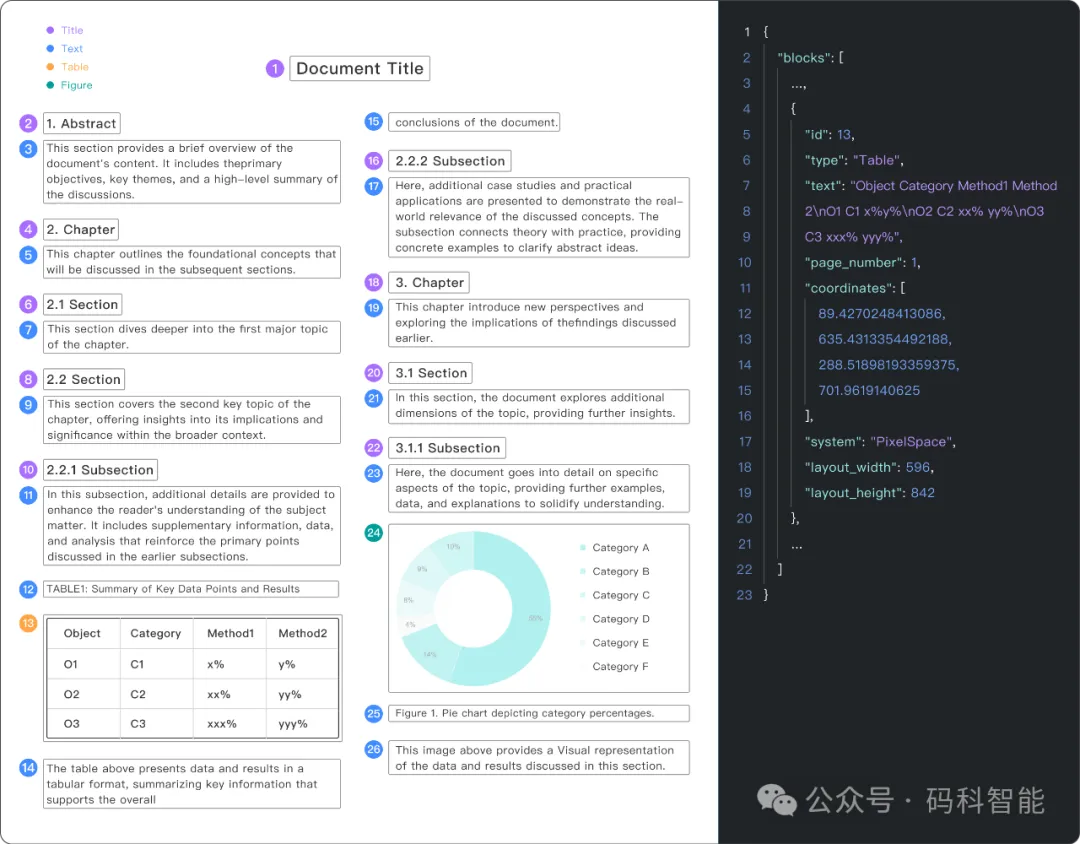
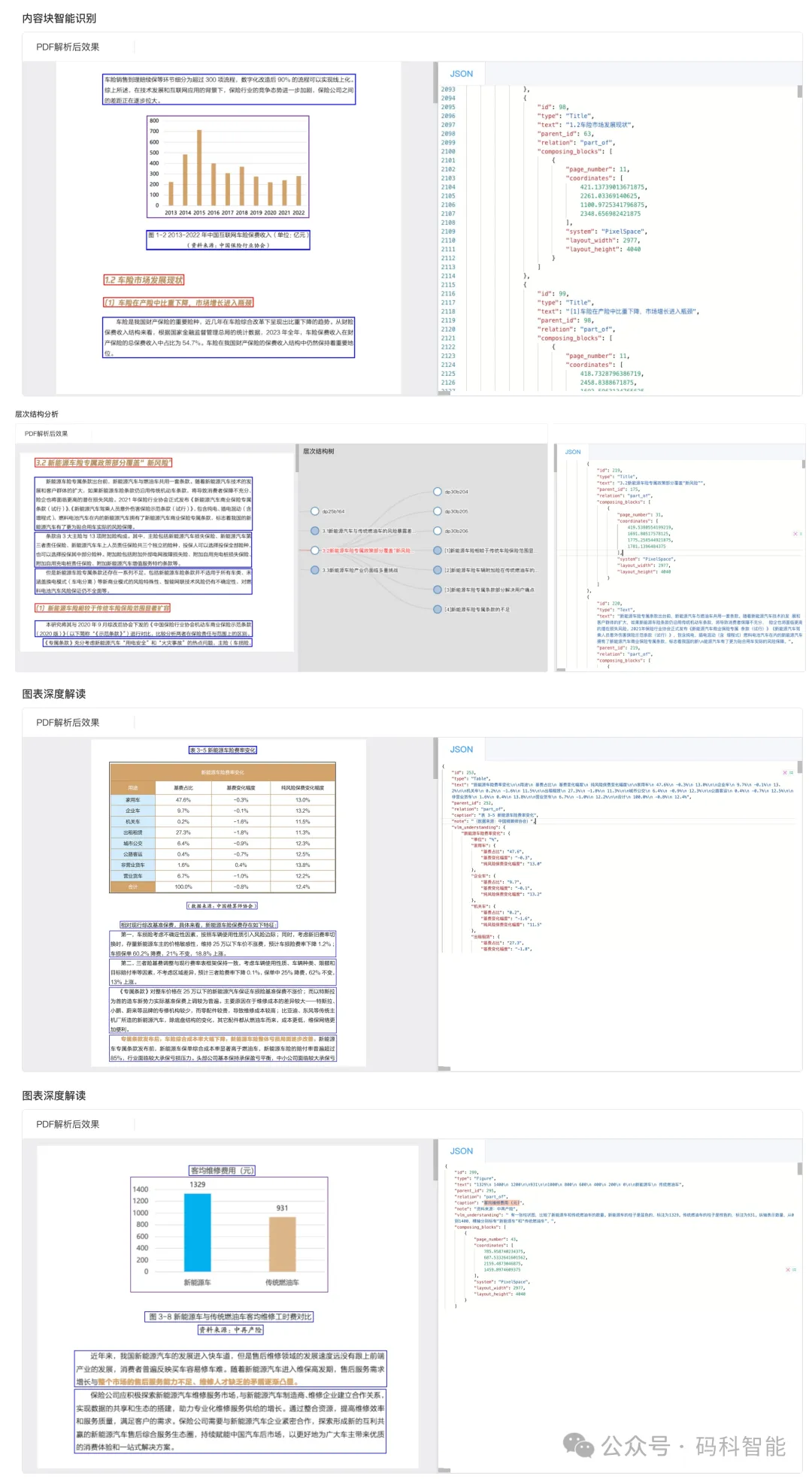
图1. 内容块智能识别,定位分析26块内容
结合我们训练大语言模型的数据处理工作,总结了下在真实业务中的文档解析痛点,主要卡在三个环节:
1. 复杂元素解析:基础OCR只能识别文字,但实际业务文档永远少不了表格、图表、图像、公式这些"硬骨头"。就拿最常见的表格来说,传统模型解析后数据关联性全乱,表格直接成了文本片段,数字和表头根本对不上号。
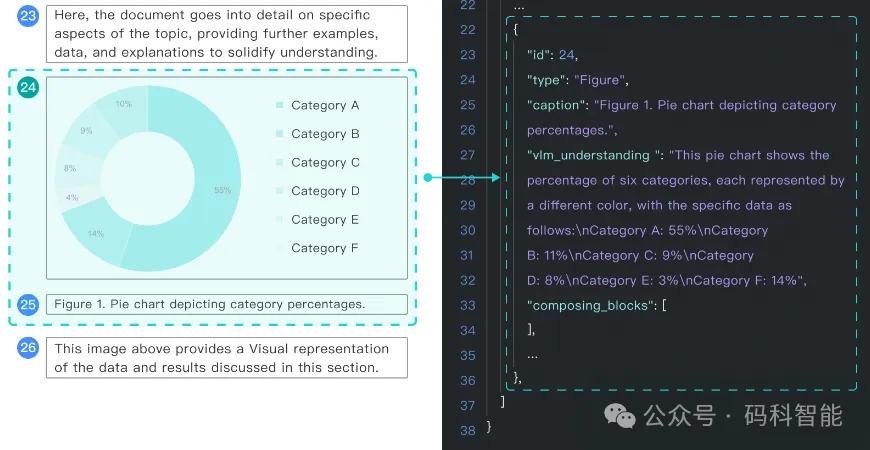
图2. 支持常见图表类型深度解读,柱状、饼状图也支持
2. 文档结构解析:现在很多模型解析完的文档,就像被碎纸机打过一样——标题层级没了,段落关系断了,图片和说明文字也分家了。
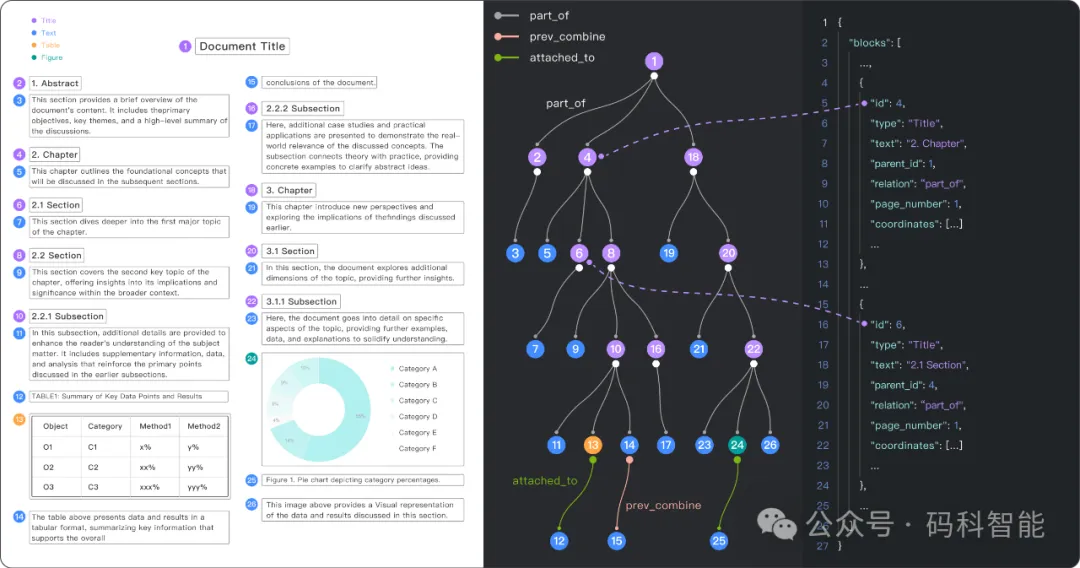
图3. 层次结构分析,构建文档结构树
3. 格式兼容性:训练大模型时最头疼的就是数据来源五花八门:PDF、Word、PPT、扫描件、TXT等等...能用一个接口搞定所有格式的工具实在太少,另外能否支持做RAG和知识库需要的格式也是令我们头疼的。
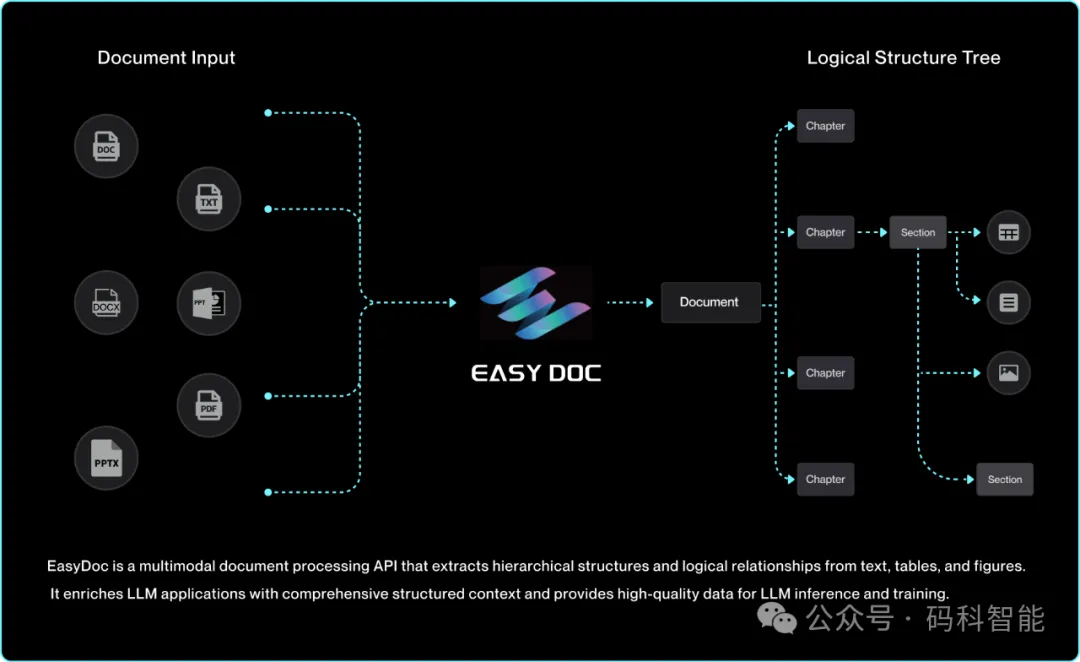
图4. 支持DOC/PPT/TXT/PDF等各种格式
更致命的是,这些解析问题会直接拖累检索增强生成RAG效果:检索时准确率低找不到关键段落,生成的答案质量差总是漏掉重要数据!
在深入剖析了文档解析的种种痛点后,我们不禁要问:是否存在一个解决方案,能够真正突破这些技术瓶颈?
一、能理解文档布局、表格及图表的工具到底是什么?经过我们团队技术调研和实测验证,我们在GitHub上发现了一款EasyDoc智能文档解析工具好像满足了我们日常的所有需求,其能深度理解文档的布局、文本、表格乃至图表,使得输出数据非常适合AI应用(如RAG、知识库构建、数据提取、报告分析)。

# 代码链接
https://github.com/easydoc-ai/easydoc
# 中文教程
https://apifox.com/apidoc/shared/704f7d88-99d0-495d-b775-dcfeb96621be
# 官网链接
https://easydoc.sh/zh{
"success": true,
"data": {
"task_id": "1a68fabb-7384-46d5-8b2e-02e3808102b3",
"task_status": "SUCCESS",
"task_result": {
"file_name": "demo_document.pdf",
"blocks": [
{
"block_id": 1,
"type": "Title",
"text": "Document Title",
"page_number": 1,
"coordinates": [
220.21530151367188,
77.08414459228516,
375.2535095214844,
100.12981414794922
],
"system": "PixelSpace",
"layout_width": 596,
"layout_height": 842
}
}

最后再说下,EasyDoc不只是简单解析文档,而是通过深度结构化理解,为RAG系统提供"认知基础设施",让AI应用能像专家一样精准理解和运用文档知识。

立即访问EasyDoc官网,获取API密钥,开启你的文档解析之旅!最后对大模型文档解析感兴趣的个人或者企业可以扫码进入EasyDoc多模态智能文档解析交流群!