大模型微调库全面对比!
本文对 Llama Factory、Unsloth 和 Hugging Face 在微调大型语言模型方面的全面性能分析!
1. 简介 🌟
大型语言模型(LLMs)的领域已经发生了巨大变化,微调已成为将这些模型部署到特定应用中的关键步骤。虽然预训练通过在大量文本语料库上使用自监督学习构建模型的基础知识,但监督式微调(SFT)则使用标记数据将这些预训练模型适应特定任务。
将预训练视为给模型提供关于世界的通用知识,而微调则像是教它一个特定职业。这个过程的专业化至关重要,因为它:
- 🎯 使模型与特定用例保持一致
- 📈 提高特定领域任务的性能
2. 微调背后的科学:文献综述 📚
现代 SFT 方法利用了几个关键技术,每个技术都基于突破性的研究:
i. 参数高效微调(PEFT)
- LoRA(低秩自适应)— https://arxiv.org/abs/2106.09685
- 通过将权重更新分解为低秩矩阵来减少训练参数 - QLoRA(量化 LoRA)— “QLoRA:高效量化LLMs微调”
- 将量化与 LoRA 结合,实现更高的内存效率
ii. 优化技术
- 混合精度训练 —“混合精度训练”
- 使用 16 位和 32 位浮点运算 - Flash Attention — “FlashAttention:具有 IO 感知的快速且内存高效的精确注意力”
- 优化注意力计算以获得更好的内存效率 - Flash Attention 2— “Flash Attention-2:更快的注意力与更好的并行性”
进一步提高注意力计算的速度和效率
大模型微调库对比

- Hugging Face Transformers🤗
- 🌟 机器学习模型行业标准
- 📚 完善的文档和社区支持
- 🌐 广泛的生态系统和模型库

2. Llama Factory
- 🚀 高效的多 GPU 支持
- ⚙️ 简化配置(yaml 文件或 UI 界面)
- 仓库: github.com/hiyouga/LLaMA-Factory

3.Unsloth
- ⚡ 新晋参与者,专注于速度优化
- 💪 单 GPU 优化
- 🧠 高级内存管理
- 仓库: github.com/unslothai/unsloth
实验设置 🧪
为了进行公平的比较,我们进行了广泛的测试,使用以下方法:
- 硬件配置 🖥️
🏭 Llama Factory:2 块 NVIDIA A100 80GB GPU
🚀 Unsloth:1 块 NVIDIA A100 80GB GPU
🤗 Hugging Face:1 块 NVIDIA A100 80GB GPU
- 数据集规格 📊
💬 大约94,000次对话
📝 总计 3500 万个 token
- 模型和训练参数 ⚙️
基础模型:🦙 Llama 3.1 8B Instruct
LoRA 配置:
🎯 排名:42
🎮 Alpha:72
💧 Dropout:0.1
不同超参数:
📏 最大序列长度:256,512,1024,2048
📦 批处理大小:4,8,16,32,64
🔄 迭代次数:15
结果与分析
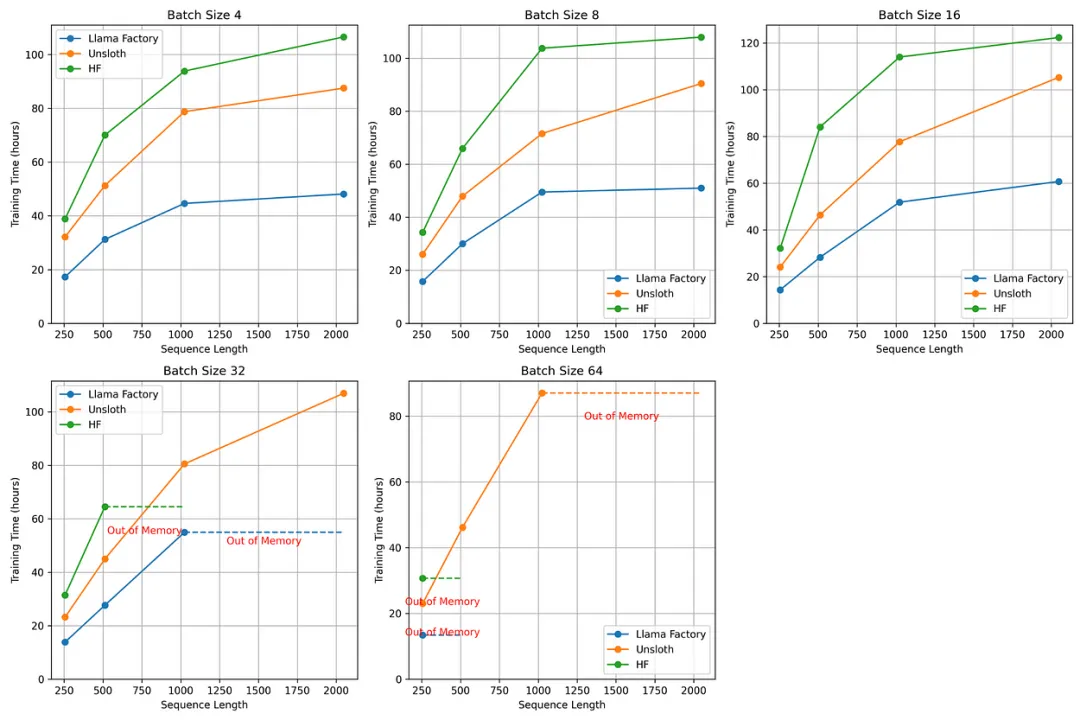
训练时间分析 📊
- 序列长度影响 ⚡
所有曲线的上升趋势都表明序列长度对训练时间的影响非常显著。这主要是因为注意力机制的二次复杂度(n²)——当序列长度加倍时,计算成本会翻四倍。这解释了为什么当我们从 256 个令牌增加到 2048 个令牌时,训练时间的增加会更加陡峭。🔄
相对性能 📈
Llama Factory 双 GPU 演示:
⚡ 比 Unsloth 快 33%
🔥 比 Hugging Face 快 54%
💪 更好的扩展性,支持更大的批量大小
内存管理 🧠
Unsloth 在内存效率方面表现出特别令人印象深刻的性能:
💪 可保持至批大小32的稳定性,序列长度可达2048
🚀 仅在批大小64时出现内存不足,序列长度1024+
⭐ 比 HF 表现更优,HF 在批大小 32、序列长度 1024 时更早出现内存不足