谷歌重磅开源Gemma 3:27B碾压DeepSeek-V3-671B,单GPU就能跑!【教程奉上】
添加微信号:LiteAI01,小助手会拉你进群!
2025年3月,谷歌扔出一颗重磅炸弹——Gemma 3,一个开源AI模型,直接挑战传统思维!它不仅能看图说话、懂140多种语言,还能在单块GPU上干翻那些需要32台服务器的庞然大物。最夸张的是,27B参数的它,性能直逼Llama3-405B、DeepSeek-V3-671B、o3-mini,效率高到离谱。更劲爆的是,它完全开源,全球开发者已经用它搞出6万多个“玩法”,从东南亚方言翻译到保加利亚AI助手,脑洞大开到你不敢信。想知道这背后藏着什么秘密?它凭什么这么牛?

Gemma3
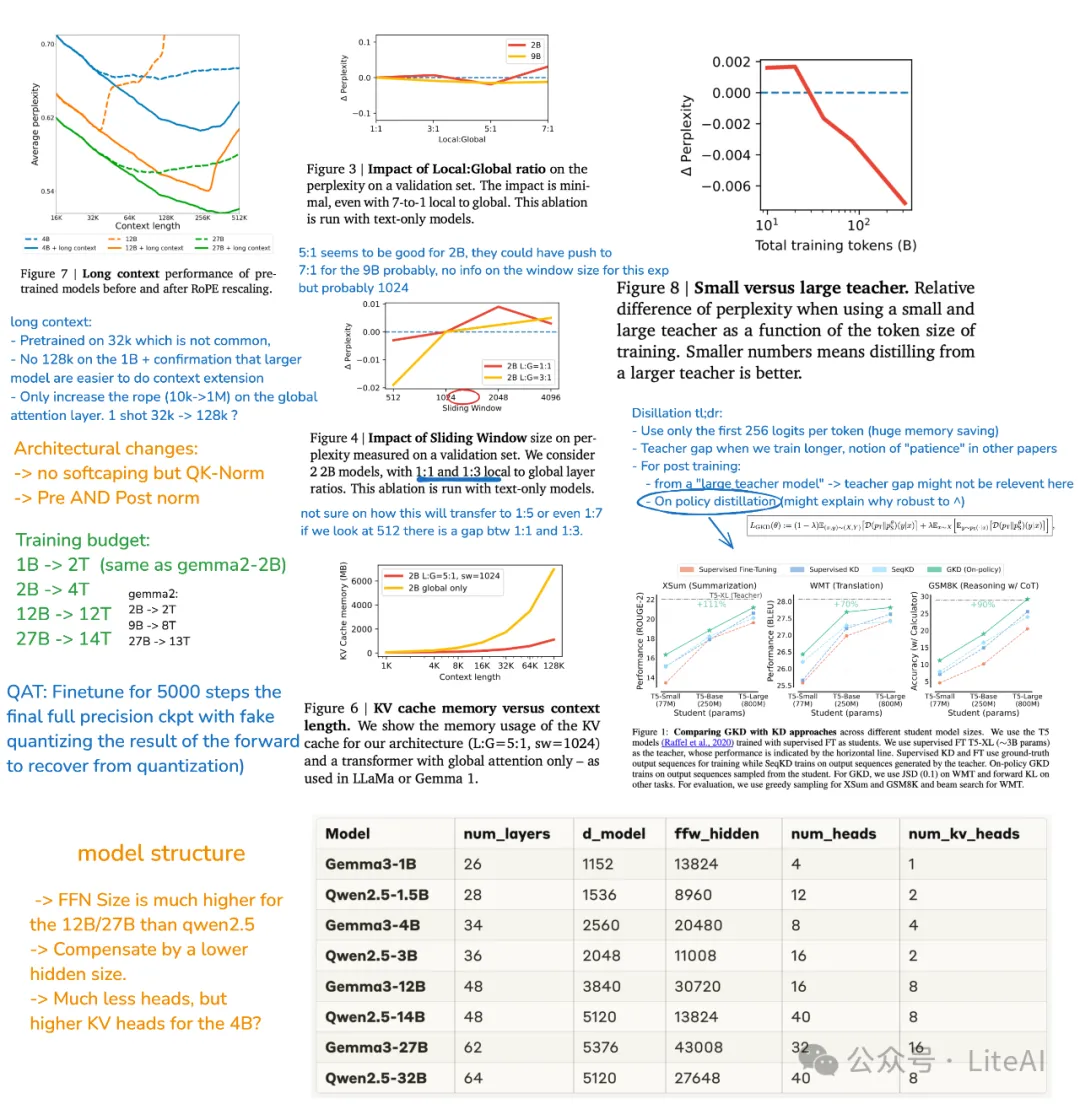
Gemma 3是 Google 最新推出的开源 LLM。它有四种大小,分别为1B、4B、12B 和27B 参数,并带有预训练和指令微调版本。Gemma 3 是多模态模型!4B、12B 和27B 参数模型可以处理图像和文本,而 1B 版本只能处理文本。
对于 1B 版本,输入上下文窗口长度已从 Gemma 2 的 8k 增加到32k ,对于其他所有版本,则增加到 128k。与其他 VLM(视觉语言模型)一样,Gemma 3 会根据用户输入生成文本,这些文本可能由文本组成,也可能由图像组成。示例用途包括问答、分析图像内容、总结文档等。

Gemma 3 核心功能
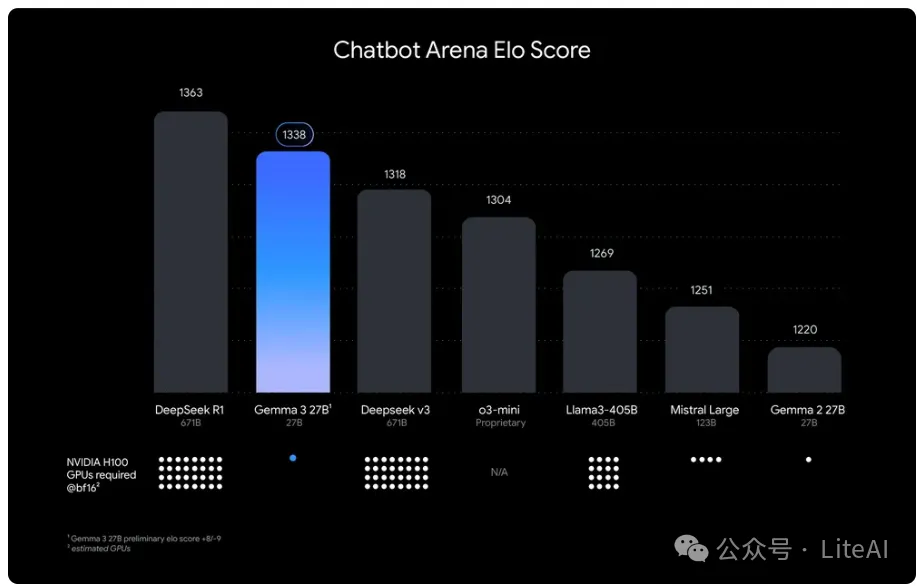
在 LMArena 排行榜的初步人类偏好评估中胜过 Llama3-405B、DeepSeek-V3-671B 和 o3-mini。
添加微信号:LiteAI01,小助手会拉你进群!
2025年3月,谷歌扔出一颗重磅炸弹——Gemma 3,一个开源AI模型,直接挑战传统思维!它不仅能看图说话、懂140多种语言,还能在单块GPU上干翻那些需要32台服务器的庞然大物。最夸张的是,27B参数的它,性能直逼Llama3-405B、DeepSeek-V3-671B、o3-mini,效率高到离谱。更劲爆的是,它完全开源,全球开发者已经用它搞出6万多个“玩法”,从东南亚方言翻译到保加利亚AI助手,脑洞大开到你不敢信。想知道这背后藏着什么秘密?它凭什么这么牛?
Gemma3
Gemma 3是 Google 最新推出的开源 LLM。它有四种大小,分别为1B、4B、12B 和27B 参数,并带有预训练和指令微调版本。Gemma 3 是多模态模型!4B、12B 和27B 参数模型可以处理图像和文本,而 1B 版本只能处理文本。
对于 1B 版本,输入上下文窗口长度已从 Gemma 2 的 8k 增加到32k ,对于其他所有版本,则增加到 128k。与其他 VLM(视觉语言模型)一样,Gemma 3 会根据用户输入生成文本,这些文本可能由文本组成,也可能由图像组成。示例用途包括问答、分析图像内容、总结文档等。
Gemma 3 核心功能
在 LMArena 排行榜的初步人类偏好评估中胜过 Llama3-405B、DeepSeek-V3-671B 和 o3-mini。支持 140 种语言:构建使用客户语言的应用程序。Gemma 3 支持超过 35 种语言开箱即用,以及对超过 140 种语言的预训练支持。
具备高级文本和视觉推理能力:轻松构建分析图片、文本、短视频等应用,开启交互智能化新可能。
使用扩展的上下文窗口处理复杂任务: Gemma 3 提供 128k token上下文窗口。
使用函数调用创建 AI 驱动的工作流程: Gemma 3 支持函数调用和结构化输出。
通过量化模型实现高性能: Gemma 3 引入了官方量化版本,减少了模型大小和计算要求,同时保持了高精度。
Gemma 3 评估
LMSys Elo 根据语言模型在面对面比赛中的表现对其进行排名,并根据人类的偏好进行判断。在 LMSys Chatbot Arena 上,Gemma 3 27B IT 的 Elo 分数为1339,跻身前 10 最佳模型之列,包括领先的闭源模型。Elo 与 o1-preview 相当,并且高于其他非思考类开源模型。与表中的其他 LLM 一样,Gemma 3 仅处理文本输入即可获得此分数。

Gemma 3 已通过 MMLU-Pro(27B:67.5)、LiveCodeBench(27B:29.7)和 Bird-SQL(27B:54.4)等基准测试进行评估,与闭源 Gemini 模型相比,其性能更具竞争力。GPQA Diamond(27B:42.4)和 MATH(27B:69.0)等测试凸显了其推理和数学能力,而 FACTS Grounding(27B:74.9)和 MMMU(27B:64.9)则展示了强大的事实准确性和多模态能力。然而,它在 SimpleQA(27B:10.0)的基本事实方面落后。与 Gemini 1.5 模型相比,Gemma 3 很接近,有时甚至更好,证明了其作为可访问、高性能选项的价值。

使用 🤗 transformer 进行推理
安装稳定版Gemma 3 transformers
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3使用Pipeline进行推理
开始使用 Gemma 3最简单的方法是使用pipeline transformers。
import torchfrom transformers import pipelinepipe = pipeline("image-text-to-text",model="google/gemma-3-4b-it", # "google/gemma-3-12b-it", "google/gemma-3-27b-it"device="cuda",torch_dtype=torch.bfloat16)messages = [{"role": "user","content": [{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},{"type": "text", "text": "What animal is on the candy?"}]}]output = pipe(text=messages, max_new_tokens=200)print(output[0]["generated_text"][-1]["content"])

可以将图像与文本交错。为此,只需在要插入图像的位置截断输入文本,然后使用如下所示的图像块插入它即可。
messages = [{"role": "system","content": [{"type": "text", "text": "You are a helpful assistant."}]},{"role": "user","content": [{"type": "text", "text": "I'm already using this supplement "},{"type": "image", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/IMG_3018.JPG"},{"type": "text", "text": "and I want to use this one too "},{"type": "image", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/IMG_3015.jpg"},{"type": "text", "text": " what are cautions?"},]},]
使用 Transformer 进行详细推理
Transformer 集成有两个新的模型类:
Gemma3ForConditionalGeneration:适用于4B、12B和27B视觉语言模型。
Gemma3ForCausalLM:对于 1B 纯文本模型,并将视觉语言模型记载,就像加载语言模型一样。
在下面的代码片段中,使用模型来查询图像。Gemma3ForConditionalGeneration类用于实例化视觉语言模型变体。要使用模型,需要将它与类AutoProcessor配对。运行推理就像创建messages字典那么简单,然后在上面应用聊天模板,再处理输入和调用model.generate。
import torchfrom transformers import AutoProcessor, Gemma3ForConditionalGenerationckpt = "google/gemma-3-4b-it"model = Gemma3ForConditionalGeneration.from_pretrained(ckpt, device_map="auto", torch_dtype=torch.bfloat16,)processor = AutoProcessor.from_pretrained(ckpt)messages = [{"role": "user","content": [{"type": "image", "url": "https://huggingface.co/spaces/big-vision/paligemma-hf/resolve/main/examples/password.jpg"},{"type": "text", "text": "What is the password?"}]}]inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True,return_dict=True, return_tensors="pt").to(model.device)input_len = inputs["input_ids"].shape[-1]generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)generation = generation[0][input_len:]decoded = processor.decode(generation, skip_special_tokens=True)print(decoded)

对于 LLM推理,可以使用Gemma3ForCausalLM类。Gemma3ForCausalLM应与 AutoTokenizer 配对进行处理。需要使用聊天模板来预处理我们的输入。Gemma 3 使用非常简短的系统提示,然后是用户提示,如下所示:
import torchfrom transformers import AutoTokenizer, Gemma3ForCausalLMckpt = "google/gemma-3-4b-it"model = Gemma3ForCausalLM.from_pretrained(ckpt, torch_dtype=torch.bfloat16, device_map="auto")tokenizer = AutoTokenizer.from_pretrained(ckpt)messages = [[{"role": "system","content": [{"type": "text", "text": "You are a helpful assistant who is fluent in Shakespeare English"},]},{"role": "user","content": [{"type": "text", "text": "Who are you?"},]},],]inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=True,return_dict=True, return_tensors="pt").to(model.device)input_len = inputs["input_ids"].shape[-1]generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)generation = generation[0][input_len:]decoded = tokenizer.decode(generation, skip_special_tokens=True)print(decoded)

在低资源设备上运行
Gemma 3 非常适合on-device使用,这是快速入门的方法。
MLX
Gemma 3 支持mlx-vlm,这是一个用于在 Apple Silicon 设备(包括 Mac 和 iPhone)上运行视觉语言模型的开源库。
首先安装mlx-vlm:
pip install git+https://github.com/Blaizzy/mlx-vlm.gitmlx-vlm安装后,可以使用以下命令开始推理:
python -m mlx_vlm.generate --model mlx-community/gemma-3-4b-it-4bit --max-tokens 100 --temp 0.0 --prompt "What is the code on this vehicle??"--image https://farm8.staticflickr.com/7212/6896667434_2605d9e181_z.jpg

Llama.cpp
可以从此集合https://huggingface.co/collections/ggml-org/gemma-3-67d126315ac810df1ad9e913下载预量化的 GGUF 文件。
请参阅该指南来构建或下载预构建的二进制文件:https://github.com/ggml-org/llama.cpp ?tab=readme-ov-file#building-the-project。
然后可以从终端运行本地聊天服务器:
./build/bin/llama-cli -m ./gemma-3-4b-it-Q4_K_M.gguf
输出:
who are youI'm Gemma, a large language model created by the Gemma team at Google DeepMind. I’m an open-weights model, which means I’m widely available for public use!