买完DeepSeek一体机,有人气懵了,有人赢麻了!
最近,很多用户都在私有化部署“DeepSeek大模型一体机”,
并且已经上线跑起来了,
大家都知道,插满GPU的DeepSeek大模型一体机不便宜,少则十几万,满血版的都是百万起、甚至大几百万。
一体机上线之后,效果到底怎么样?
这钱花得值不值?
值不值,不能光靠感觉
需要从多个维度进行评估!
为啥有人气懵了,有人赢麻了?
今天我们就来说道说道↓
就像我们看一辆车好不好,先看它跑得快不快。
▌极限总吞吐
(TPS)
也就是每秒最高能处理多少个Tokens。
比如,有的一体机极限吞吐量是8000Token/s,有的则是3000Token/s,说明性能差距翻了两三倍。
这有硬件的原因,也有软件优化的原因。
理论上讲,极限吞吐越高,越好。这代表了一台一体机的上限。
▌响应速度
说白了就是用户点一下,大模型多久能给出答案。
这个主要看两个指标:TTFT(首Token延迟)和TPOT(单Token生成时长)。
前者代表了用户发出请求到大模型吐一个字所需要的时间。后者则决定了模型持续生成内容的效率。
这点一定要注意,嘿嘿,前端的同事和领导们能直接感知到哦,是爽还是卡~
▌并发能力
能同时处理多少个用户请求,而不崩、不卡、不掉线。
比如,原来能撑500人同时用,现在1000个人用,会不会卡?
并发能力是判断大模型服务“能不能上生产”的核心标准之一。
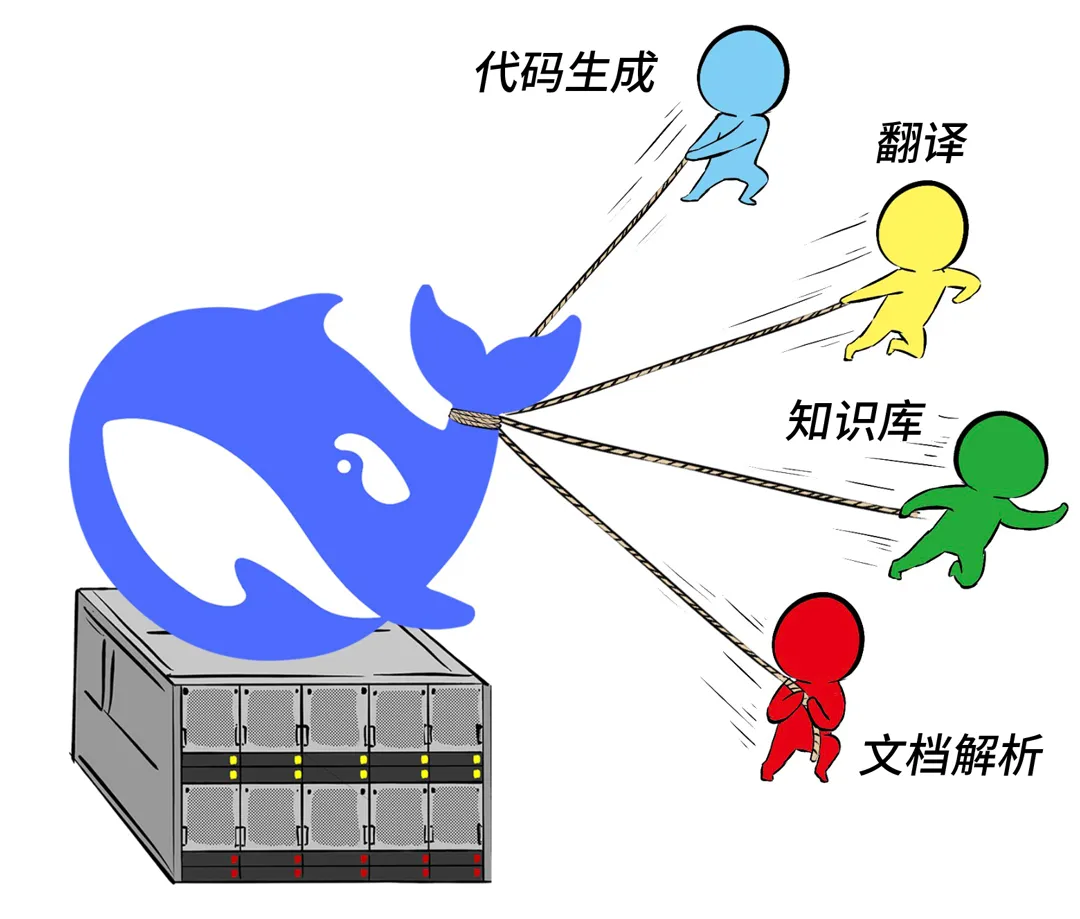
▌多场景性能体验
花大价钱买的一体机,可不是光拿来玩聊天的。
目前市面上秀出来的一体机性能,主要是极限吞吐,一般是模拟1k上下文长度的聊天会话场景,通过增大并发来获得极限吞吐。
而在企业场景,还需要看比如知识库、翻译、文章解读、代码生成等场景的具体体验。
所以,选购的时候,最好让供应商也提供相应场景的测试数据。(序列长度/并发量/TPOT/TTFT/TPS)
买设备不是“一锤子买卖”,还要看未来能不能灵活扩展、平滑升级。
别一买进入“锁死架构”。
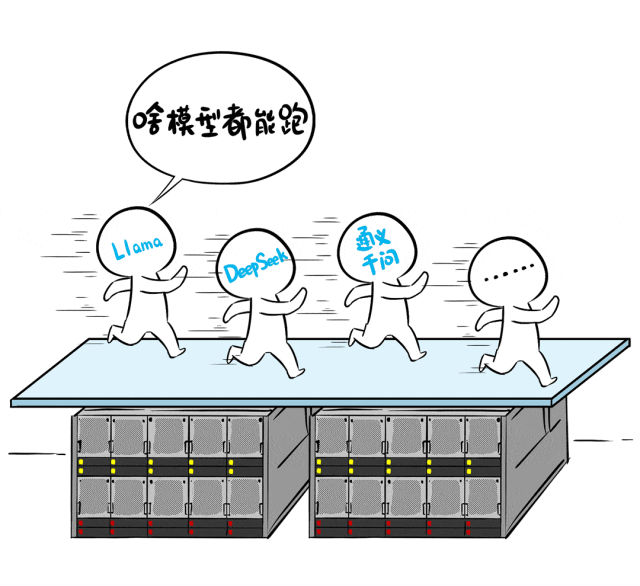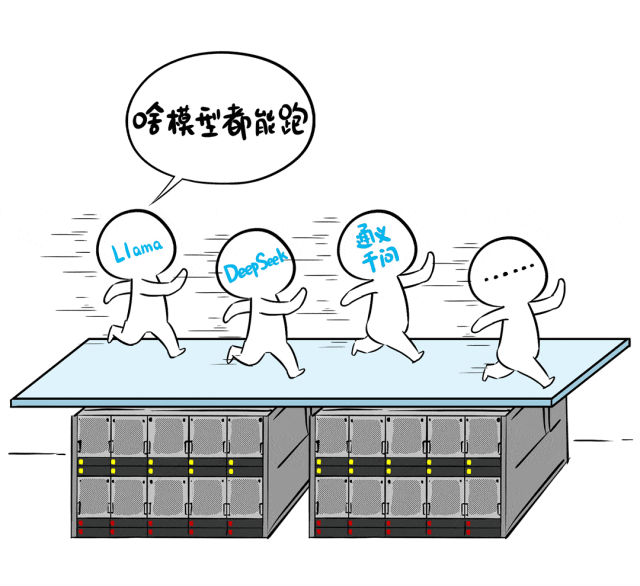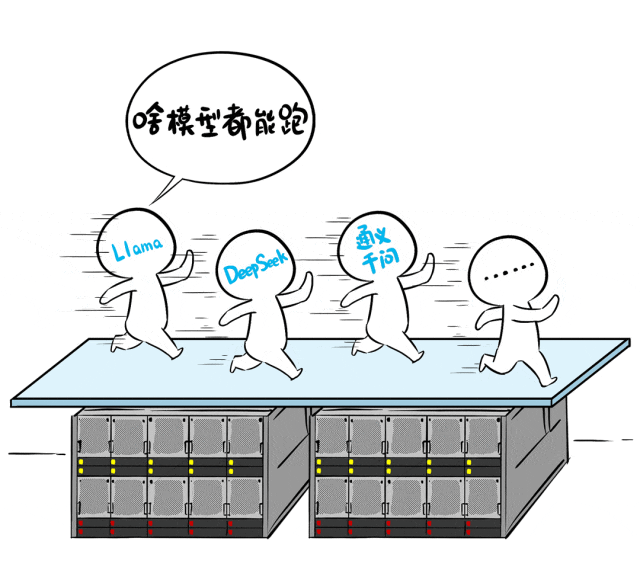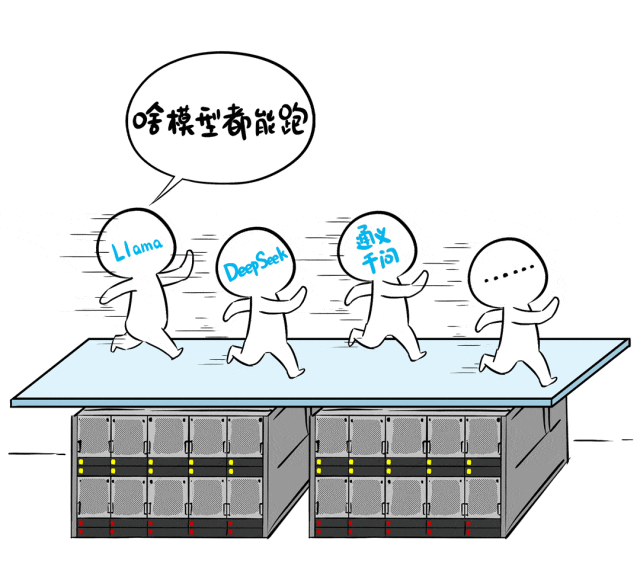
▌能否支持多种模型同时跑
能不能同时跑多个模型,如 DeepSeek、QwQ、Llama等,不被框架或资源限制住?
▌能否平滑支持集群部署
都说单机版跑DeepSeek,由于并行限制导致性能无法跑到最佳。
那么手里的一体机,未来扩展成多机、集群,有没有硬伤,多机互联有没有瓶颈?
单机的优化和多机的优化,区别很大,软件上能不能快速适应,把那些PD分离、EP并行的玩法都加上。
▌配套AI开发工具链到底有没有坑?
一体机硬件重要,配套的AI工具链同样重要。
是不是把Dify套了壳,就说是自研?
那可以要小心了,别被人家发了律师函。
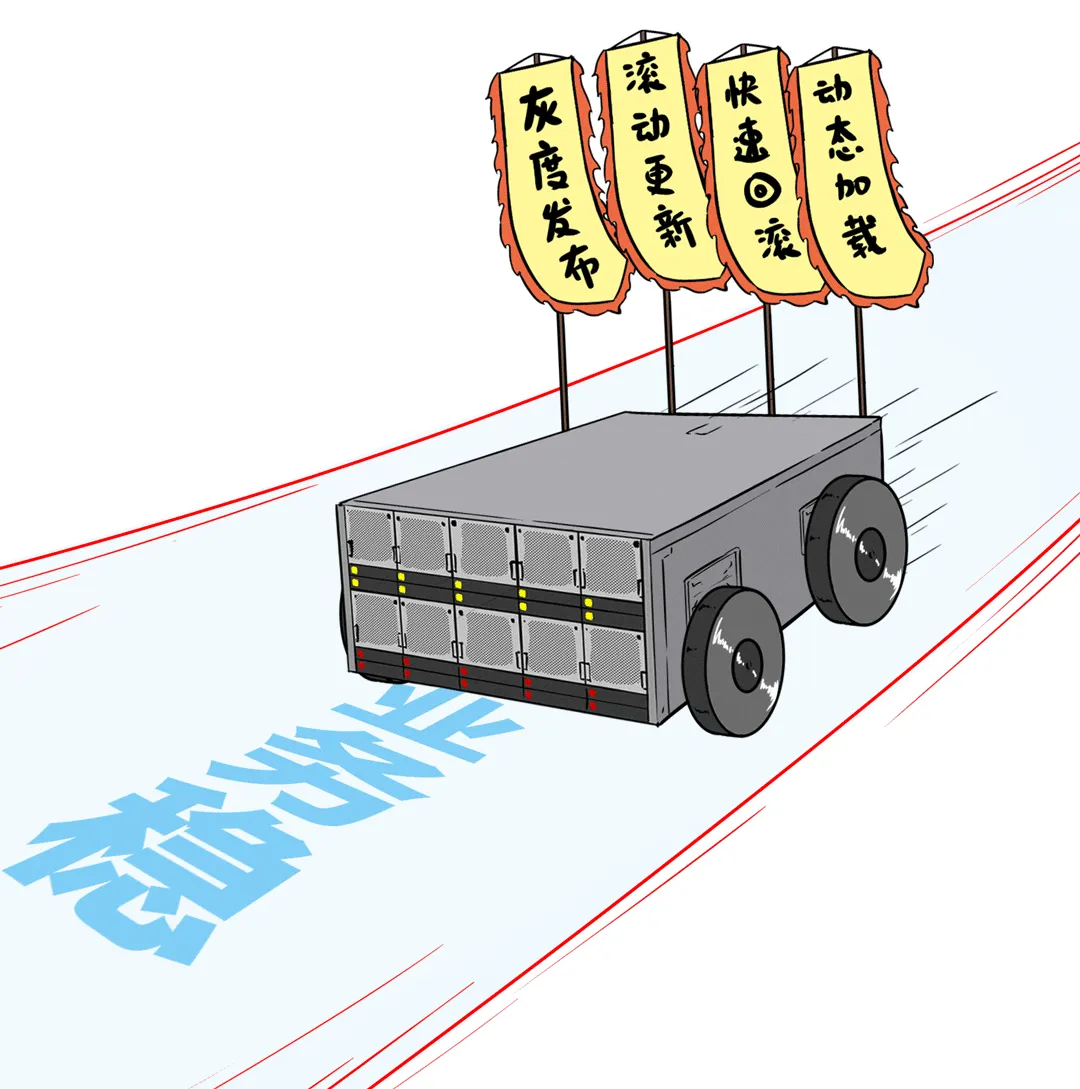
▌是否支持模型热部署与快速切换
不重启系统、不停服务的情况下,能随时切换模型、加载新模型,让系统“热着”也能换脑子!
“后台更新、前台无感知”,
这很重要!
决定了你能不能“放心大胆”地,
折腾模型、
迭代模型、可控交付、持续交付。
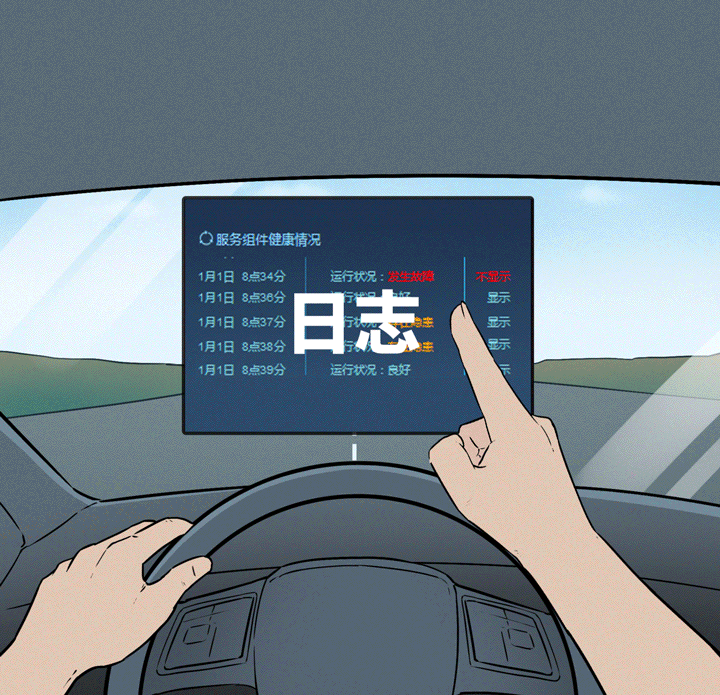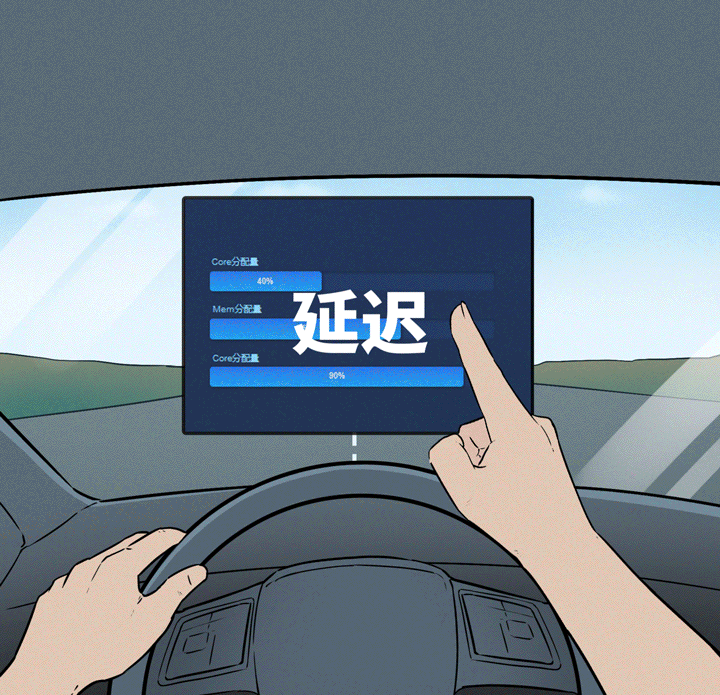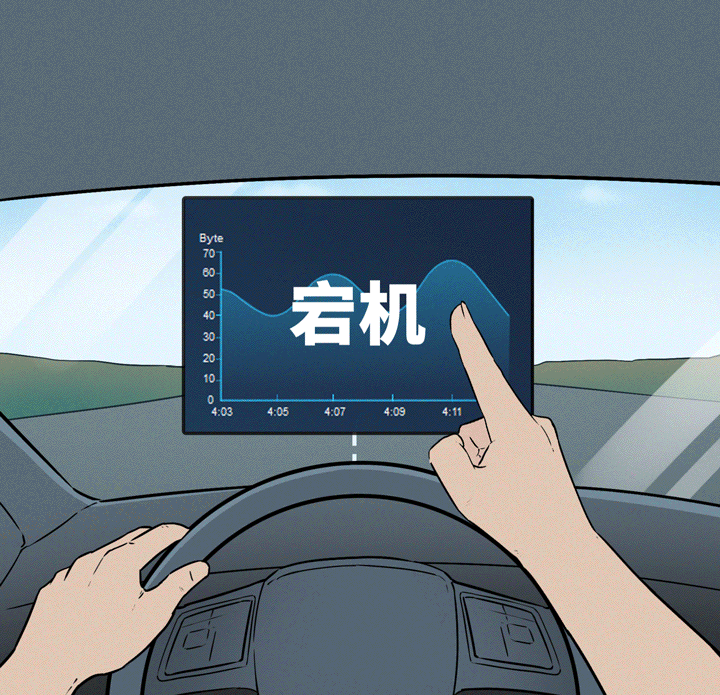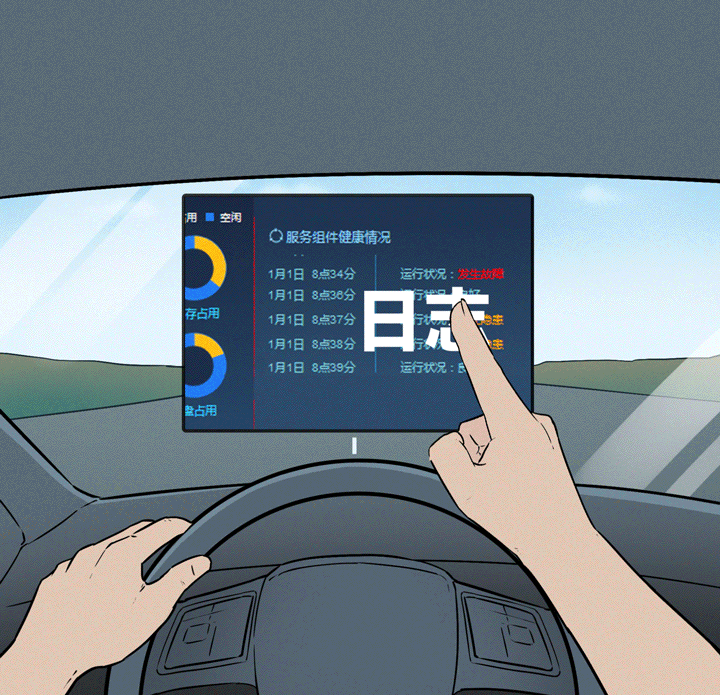
▌是否具备一套完善监控和运维机制
能把GPU、内存、延迟、模型状态这些关键指标都监起来,运维才不抓瞎。
出现宕机、推理失败、死锁、内存溢出等问题,有没有告警机制?
当然,上面这两点,在一体机采购之前,就可以进行评估、质询、测试,然后综合评定,理智避坑。
接下来的,就没那么好判断了↓
钱花得值不值?
对业务有没有帮助?老板最关心!
这才是大模型上线后最核心的评估目标!
技术再强,不能推动业务增长也白搭。
▌员工人均效率是否提升?
比如,之前一件工作需要3天,现在需要6小时,人效ROI大幅上升。
▌是否能解决具体业务问题?
比如,用大模型搞合同审核,准确率提升到80%;用大模型搞招聘,人岗匹配准确率提升 30%..
▌业务指标,有提升吗?
比如,公司的销售转化率、运营效率、客户留存率提升了吗?
说白了就是:能不能省钱或赚钱,回本快不快?
▌推理成本降了没有?
比如,原来从外面调用API,每百万Tokens要16元,私有部署后,综合摊下来只要5元,长期就能省下一大笔。
▌整体投入产出比如何?
比如,花100万部署,能不能在半年内通过效率提升或营收增长赚回来?
总之,大模型一体机项目,想要被老板和内部认可,
就看两点:
第一,情绪价值拉满
一家敢真金白银投入大模型的企业,必然是有魄力,敢投、敢试、不落后,愿意走在行业前头,而不是“落后挨打”。
内部企业员工也有自豪感,也会觉得:
“哇,我们公司可以啊,挺有前瞻性啊,干得漂亮”
第二,业务价值到位
指标亮了、效率高了、转化率提了、成本省了——说明这事干得值,是真正为业务添了把火。
情绪上赢人心,业务上有正反馈