关于智能体(AI Agent),不得不看的一篇总结
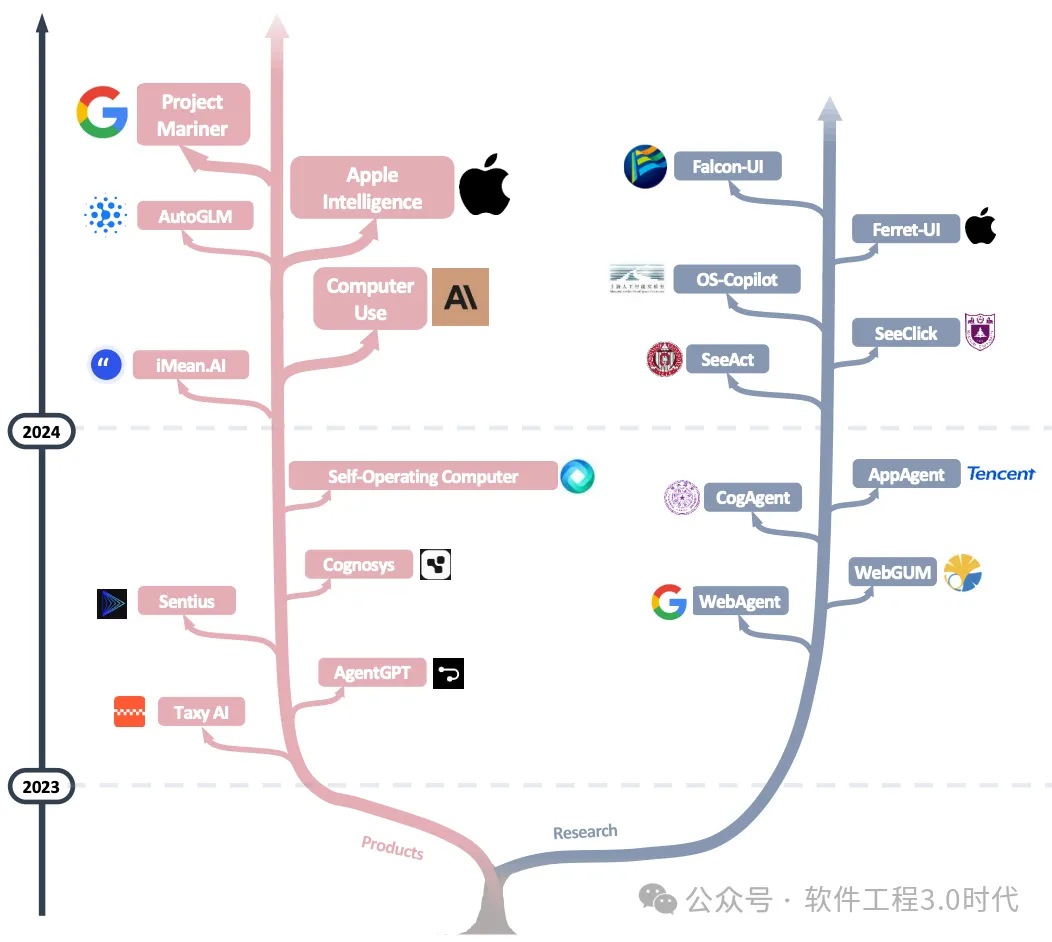
AppAgentX:Evolving GUI Agents as Proficient Smartphone Users MobileFlow:A Multimodal LLM for Mobile GUI Agent OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use SpiritSight Agent:Advanced GUI Agent with One Look.
环境:OS Agent所处的操作系统环境,如Windows、macOS、Android等 观察空间:智能体获取信息的方式,如界面截图、DOM结构等 行动空间:智能体可执行的操作集合,如点击、输入、滑动等
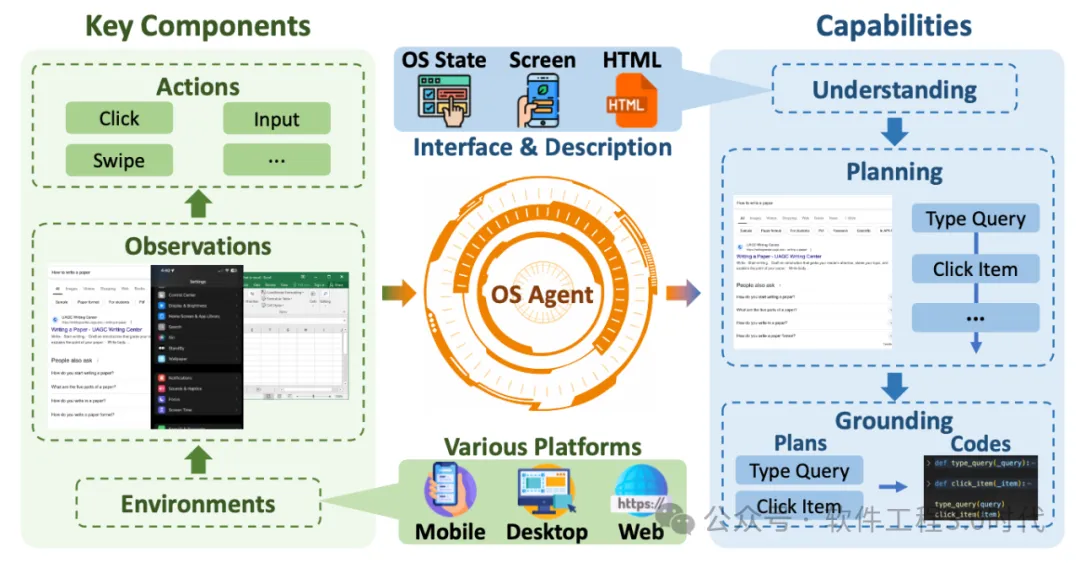
(来源于论文:OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use)
基于语言的智能体:仅使用HTML/XML等文本描述作为输入 基于视觉的智能体:仅使用屏幕截图作为输入 视觉-语言混合智能体:同时使用屏幕截图和文本描述作为输入
(来源于论文:OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use)
SpiritSight提出的Universal Block Parsing(UBP)方法解决了动态高分辨率输入中的歧义问题 MobileFlow的混合视觉编码器支持可变分辨率输入,提高了对细节的感知能力 OpenAI的ComputerUse则通过闭环视觉-操作系统直接分析整个屏幕并执行精确操作
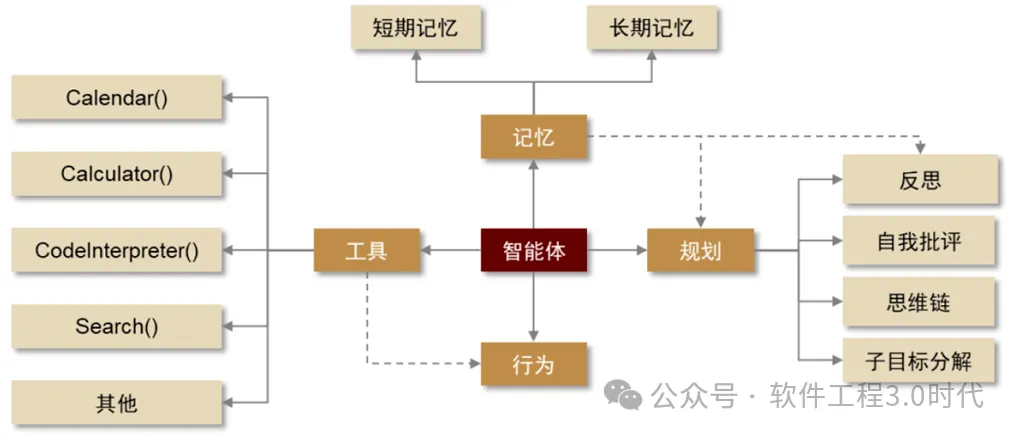
全局规划:在任务开始前规划完整的操作序列 迭代规划:根据环境反馈动态调整操作计划
鼠标/触摸操作:点击、长按、拖拽 键盘操作:文本输入、快捷键 导航操作:滚动、翻页、切换标签等。
技术原理:基于Computer-Using Agent (CUA)模型,结合GPT-4o的视觉能力和推理能力 工作流程:指令理解→动作生成→执行与反馈→状态理解→迭代改进 支持环境:浏览器、macOS、Windows、Ubuntu(暂不支持移动平台) 应用场景:自动化测试、探索式测试、回归测试、跨平台一致性测试等。
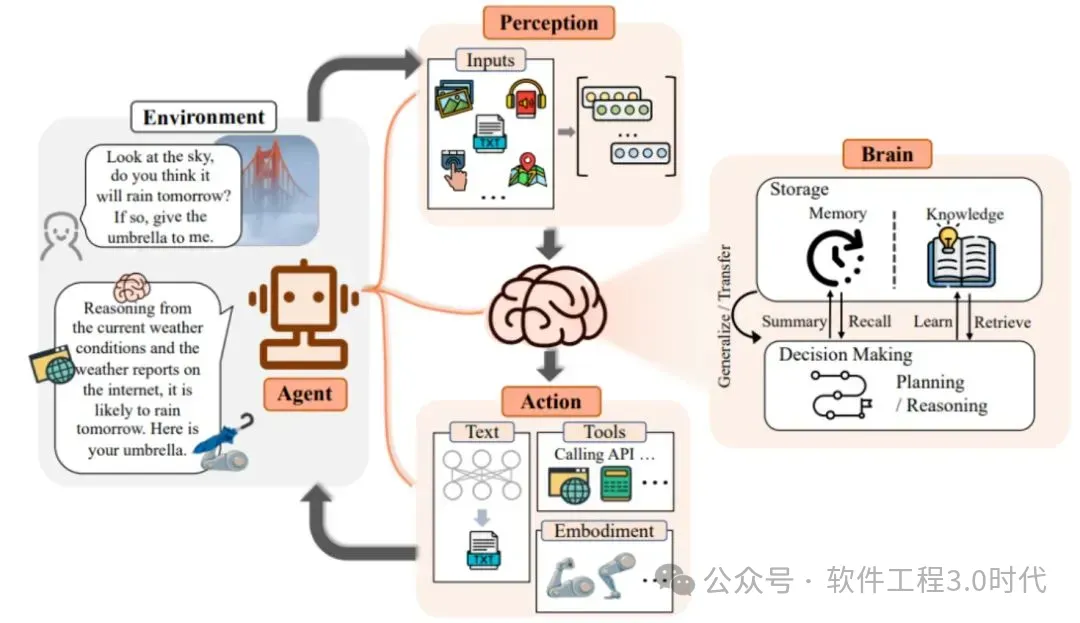
(有视觉能力的智能体)
核心创新:提出GUI-Lasagne多级大规模GUI数据集和Universal Block Parsing方法 技术特点:端到端、纯视觉感知,无需HTML/XML辅助 性能表现:在Multimodal-Mind2Web等多个基准测试中超越现有方法 跨语言能力:通过小规模目标语言数据微调,可实现跨语言(如中文)GUI操作
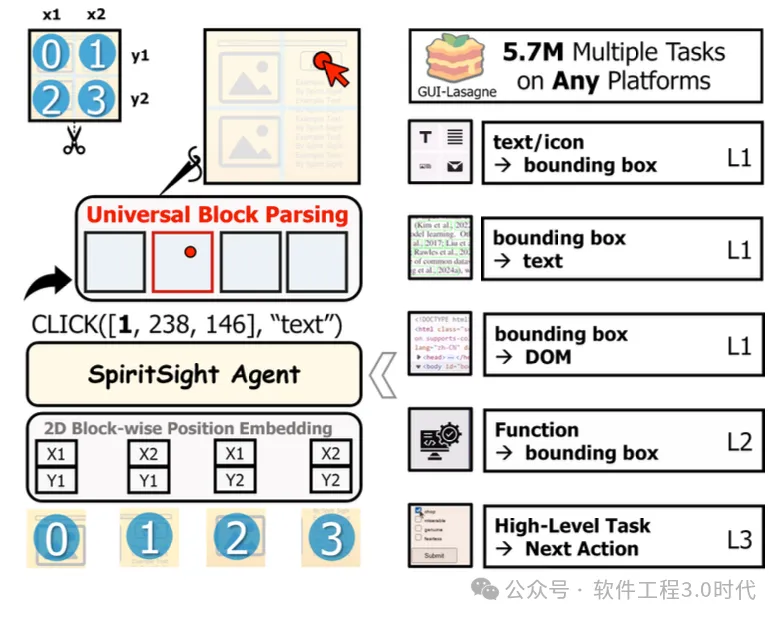
(来源论文:SpiritSight Agent:Advanced GUI Agent with One Look。SpiritSight智能体概述:借助一个大规模、多层次、高质量的预训练数据集,使 SpiritSight具备三个层次的全面GUI知识。此外引入了一种通用模块解析方法,以增强 SpiritSight的基础能力)
模型架构:基于Qwen-VL-Chat,采用混合视觉编码器,支持21B参数规模 技术特点:支持可变分辨率输入、良好的多语言支持、采用MoE结构 训练策略:GUI对齐(定位、引用、问答、描述)和GUI Chain-of-Thought 实际应用:已在软件测试和广告预览审核等场景成功部署
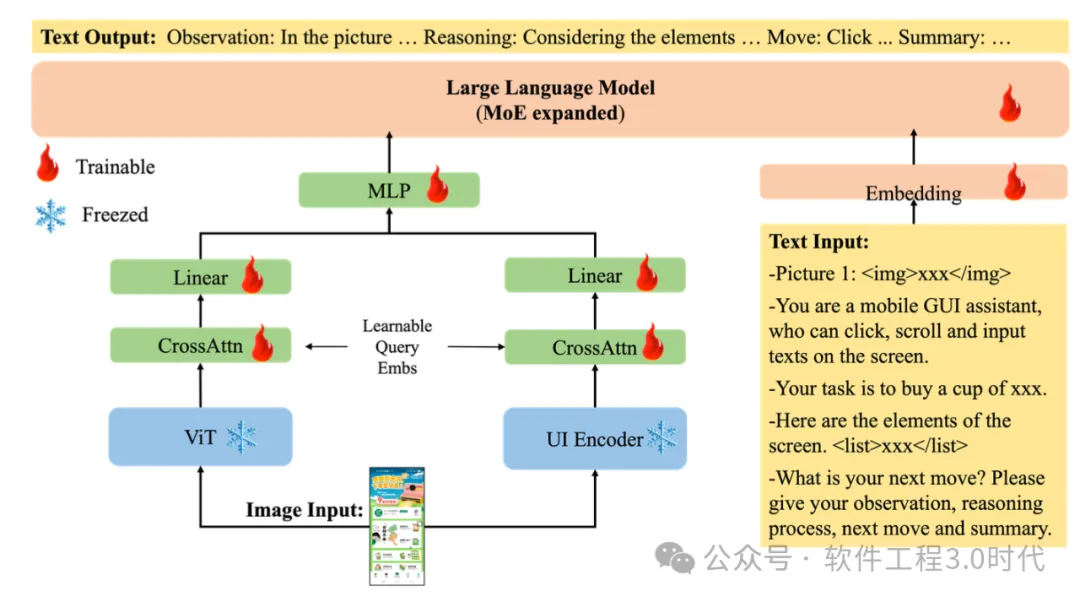
(来源论文:MobileFlow- A Multimodal LLM for Mobile GUI Agent)
关于AppAgentX,请参考文章:手工测试没有未来:进化型GUI智能体的革命
探索式测试:智能体可以自主探索应用的各个功能和界面,发现异常UI状态 回归测试:智能体记忆历史交互路径,即使界面变化也能适应并成功执行测试 跨平台测试:同时在不同设备、浏览器或操作系统上验证功能 可视化报告:提供清晰的文本描述和截图,便于开发者理解问题
电商购物:自动完成商品搜索、比较、下单、支付流程 表单填写:自动填写各类注册表单、申请表单 内容聚合:从多个应用收集信息并整合 智能助手:执行复杂的多步骤任务,如预订旅行、安排会议等
文档处理:自动创建、编辑、格式化文档 数据分析:执行数据收集、清理、分析和可视化流程 系统管理:管理文件、安装/卸载软件、系统配置等 创意工具:辅助图像编辑、视频剪辑等创意工作
可靠性问题:正如OpenAI指出,CUA模型在自动化操作系统任务方面的表现(38.1%)远低于浏览器任务 元素定位精度:尽管有UBP等新方法,元素定位仍是视觉智能体的核心挑战 长序列任务:完成需要多步骤、长时间操作的复杂任务时可靠性下降 复杂推理:涉及多页面、多条件判断的任务推理能力有限 多语言支持:非英语界面的理解和操作能力通常较弱
提示注入攻击:恶意网站或应用可能尝试通过界面元素实施提示注入攻击 隐私泄露风险:智能体在操作过程中可能接触敏感信息 操作权限管控:如何限制智能体只执行安全、授权的操作 潜在滥用:恶意使用智能体自动执行未授权操作
计算资源需求:高质量GUI智能体通常需要大型模型支持,计算开销较大 延迟问题:实时操作要求低延迟,但视觉分析和推理需要较高计算资源 系统集成:与现有工作流和系统的无缝集成需要额外开发 版本兼容性:应用界面不断更新,智能体需要持续适应新变化
自我改进能力:智能体将能从测试结果中学习,持续优化测试策略 多模态融合增强:更深入地融合视觉、文本、音频等多模态信息 领域专业化:针对特定行业应用的专业化智能体,如金融、医疗等 集成增强工具:无缝集成OCR、计算机视觉、搜索等专用工具以增强能力
统一接口:开发统一的智能体接口,适用于不同平台和设备 移动-桌面协同:实现移动设备和桌面系统间的智能协作 Web-原生应用融合:同时支持Web应用和原生应用操作 IoT设备控制:扩展到智能家居、工业控制等IoT设备界面
用户偏好学习:学习用户操作习惯和偏好 持续适应:随着用户使用方式的变化而自我调整 主动建议:基于历史数据主动提出任务优化建议 自我评估与优化:智能体自我评估性能并改进策略