终于搞懂了Transformer!超强算法模型详解,附代码资料包!

大家好,我是小编!
今天给大家分享一个超级强大的算法模型——Transformer。
这个模型在自然语言处理(NLP)领域简直是神一样的存在,尤其是2017年那篇《Attention Is All You Need》论文发布后,Transformer彻底改变了NLP的格局。
为什么Transformer这么牛?
传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在处理序列数据时,总是要一步一步来,效率低还容易出错。而Transformer通过自注意力机制(Self-Attention),直接捕捉输入序列中不同位置的关系,不仅计算速度快,还能处理超长的序列数据,效果杠杠的!
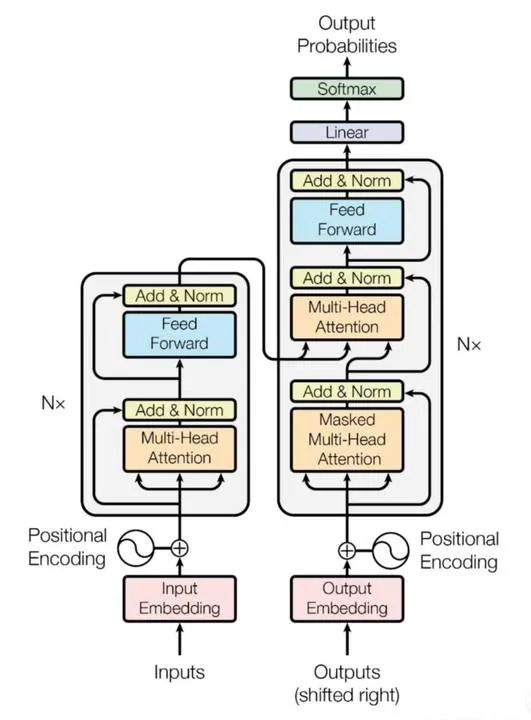
Transformer的架构
Transformer主要由两部分组成:编码器(Encoder)和解码器(Decoder)。
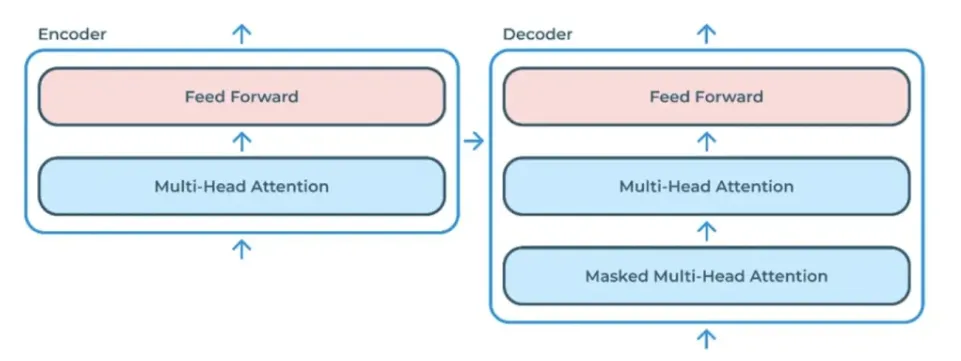
编码器:负责提取输入序列的上下文信息。
解码器:根据编码器提取的信息生成输出序列。
编码器的结构
编码器由多个相同的层堆叠而成,每一层包括两个子层:
多头自注意力机制(Multi-Head Self Attention)
前馈神经网络(Feed-Forward Neural Network)
每个子层后面都有残差连接和层归一化,这样可以提高模型的训练稳定性,加速收敛。
解码器的结构
解码器也是由多个相同的层堆叠而成,每一层包括三个子层:
掩蔽多头自注意力机制(Masked Multi-Head Self-Attention)
编码器-解码器注意力机制(Encoder-Decoder Attention)
前馈神经网络(Feed-Forward Network)
同样,每个子层后面也有残差连接和层归一化。
Transformer的核心组件
1. 输入嵌入(Embedding)
Transformer不能直接处理文字,所以需要把输入的单词或词片段(token)转换成向量表示。这个过程叫做嵌入(Embedding)。每个词都被映射到一个固定大小的向量空间中,通常是通过一个训练好的词向量矩阵来实现的。
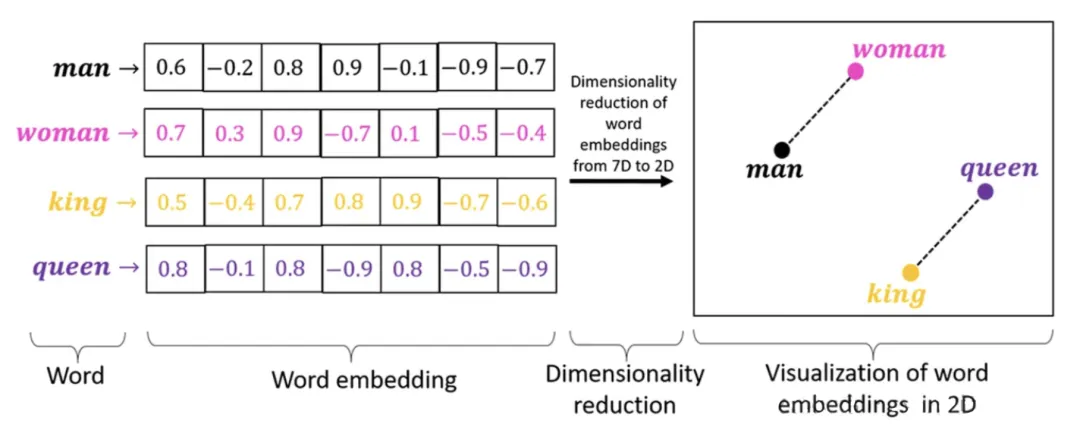
作用:把离散的文本数据变成连续的向量,方便神经网络处理,还能捕捉语义信息(比如“国王”和“皇后”在向量空间中会很接近)。
2. 位置编码(Positional Encoding)
Transformer没有循环结构,所以它不知道词的顺序。为了让它知道词的位置,我们引入了位置编码。位置编码通常用正弦和余弦函数来生成,然后加到输入嵌入上。
作用:让Transformer知道词的顺序,处理序列数据时不会乱。
import mathimport torchimport torch.nn as nnclass PositionalEncoding(nn.Module):def __init__(self, embed_size, max_len=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, embed_size)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.pe = pe.unsqueeze(0) # (1, max_len, embed_size)def forward(self, x):return x + self.pe[:, :x.size(1)].to(x.device)
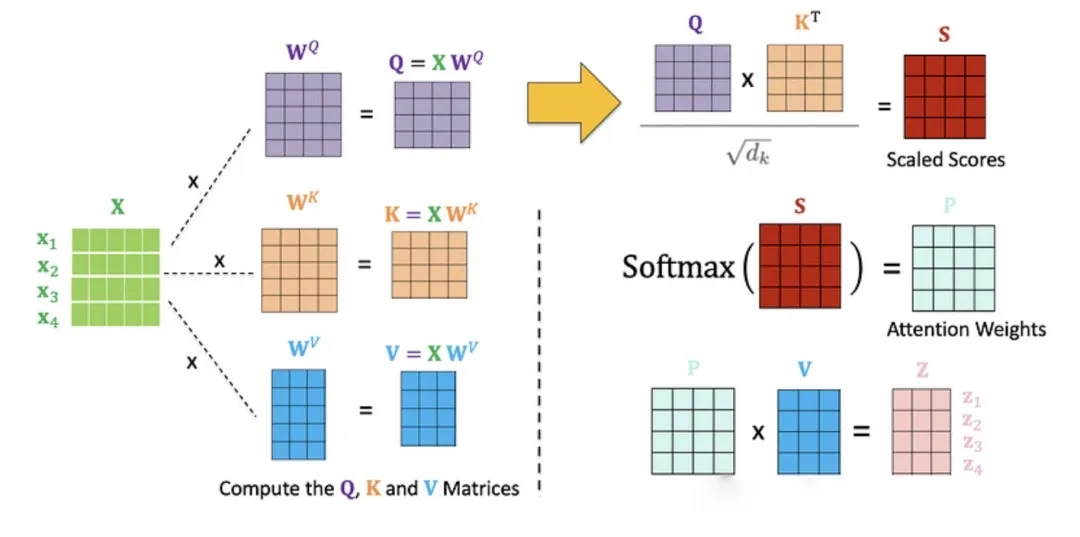
3. 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心,它能捕捉输入序列中每个词与其他词的关系。具体步骤如下:
生成Query、Key和Value矩阵。
计算Query和Key的点积,得到注意力得分。
对得分进行softmax操作,得到注意力权重。
用权重对Value矩阵加权求和,得到输出。
def scaled_dot_product_attention(Q, K, V, mask=None):d_k = Q.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))attention_weights = torch.nn.functional.softmax(scores, dim=-1)output = torch.matmul(attention_weights, V)return output, attention_weights# 示例Q = torch.rand(10, 64) # 查询矩阵K = torch.rand(10, 64) # 键矩阵V = torch.rand(10, 64) # 值矩阵output, attn_weights = scaled_dot_product_attention(Q, K, V)print(output.shape)
4. 多头自注意力机制(Multi-Head Attention)
单一的自注意力机制可能不够强大,所以Transformer引入了多头自注意力机制。通过并行计算多个自注意力头,模型可以捕捉到输入序列中不同子空间的信息,增强表达能力。

class MultiHeadAttention(nn.Module):def __init__(self, embed_size, num_heads):super(MultiHeadAttention, self).__init__()assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"self.num_heads = num_headsself.head_dim = embed_size // num_headsself.W_q = nn.Linear(embed_size, embed_size)self.W_k = nn.Linear(embed_size, embed_size)self.W_v = nn.Linear(embed_size, embed_size)self.W_o = nn.Linear(embed_size, embed_size)def forward(self, Q, K, V, mask=None):batch_size = Q.shape[0]Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)K = self.W_k(K).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)V = self.W_v(V).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)attn_output, _ = scaled_dot_product_attention(Q, K, V, mask)attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)return self.W_o(attn_output)embed_size = 512num_heads = 8multihead_attention = MultiHeadAttention(embed_size, num_heads)Q = torch.rand(2, 10, embed_size)output = multihead_attention(Q, Q, Q)print(output.shape)
5. 前馈神经网络(Feed-Forward Network)
在每个自注意力层后面,Transformer都会接一个前馈神经网络(FFN),用来对每个位置的表示进行非线性变换,增强模型的表达能力。
class FeedForward(nn.Module):def __init__(self, embed_size, hidden_dim):super(FeedForward, self).__init__()self.fc1 = nn.Linear(embed_size, hidden_dim)self.fc2 = nn.Linear(hidden_dim, embed_size)self.relu = nn.ReLU()def forward(self, x):return self.fc2(self.relu(self.fc1(x)))
6. 残差连接(Residual Connection)
残差连接就是把输入直接加到子层的输出上,这样可以缓解深层网络中的梯度消失问题,让训练更稳定。
7. 层归一化(Layer Normalization)
层归一化用来稳定训练,防止梯度爆炸或消失。它作用在每个样本的特征维度上,特别适合序列任务。
8. 掩蔽多头自注意力机制(Masked Multi-Head Attention)
在解码器中,为了防止模型在预测时“偷看”未来的词,我们使用掩蔽多头自注意力机制。通过掩蔽矩阵,模型只能看到当前词和之前的词。
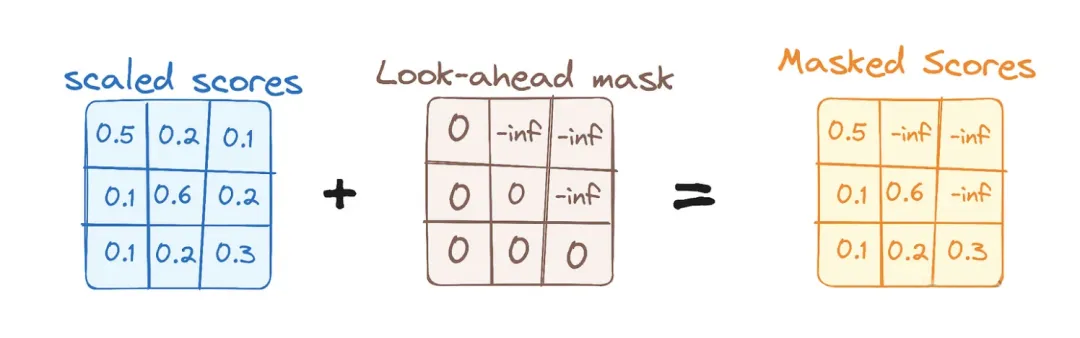
9. 编码器-解码器注意力机制(Encoder-Decoder Attention)
解码器通过这个机制来关注编码器的输出,提取源序列的上下文信息,帮助生成更准确的输出。