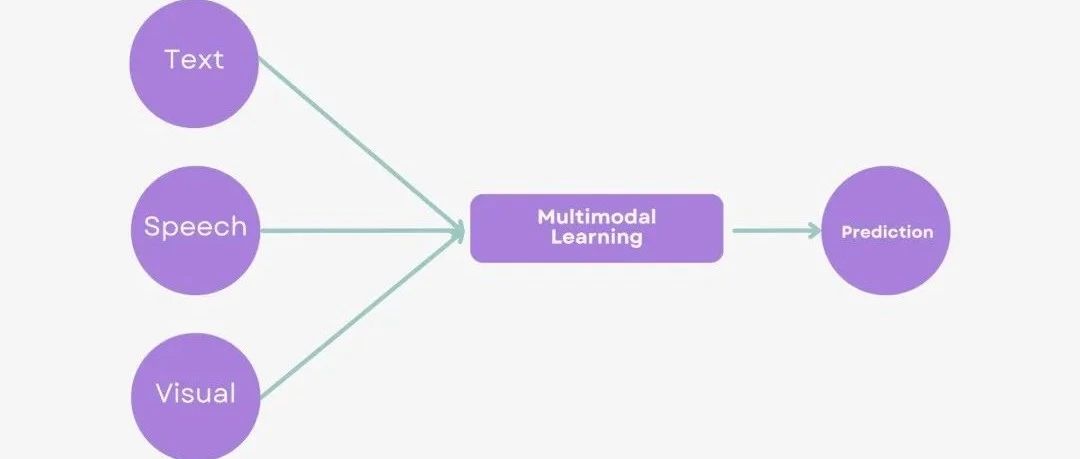
一文搞懂多模态学习(多模态融合 + 跨模态对齐)

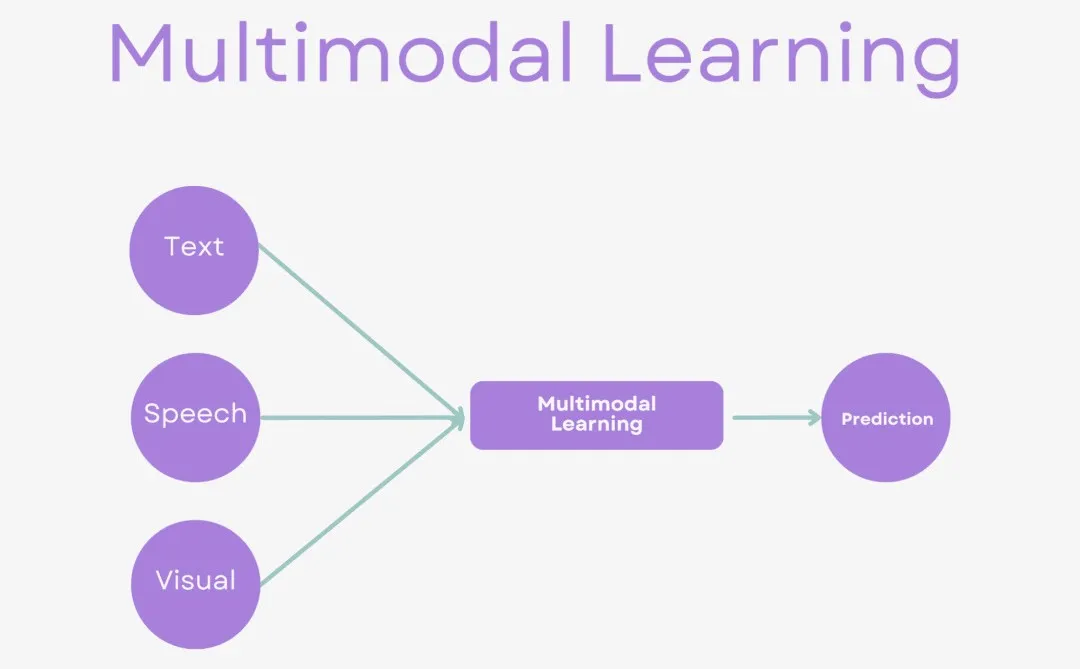
一、多模态融合:整合信息
什么是多模态融合(MultiModal Fusion)?多模态融合能够充分利用各模态之间的互补优势,将来自不同模态的信息整合成一个稳定且全面的多模态表征。
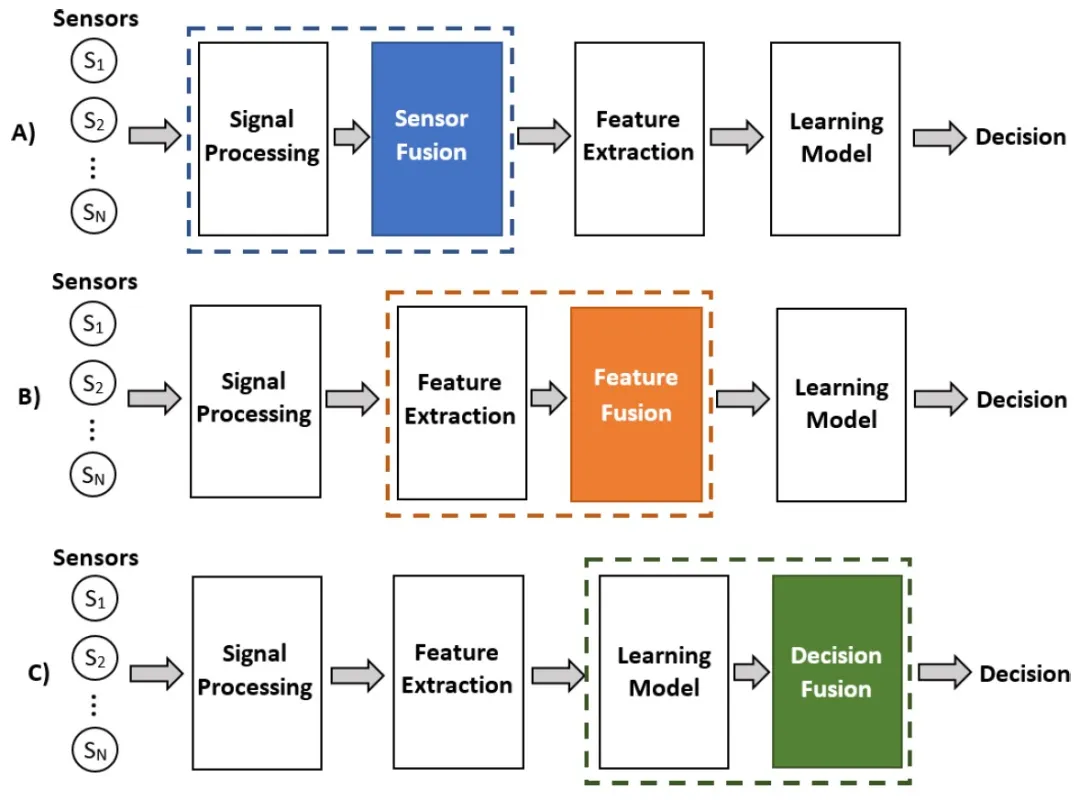
从数据处理的层次角度来划分,多模态融合可分为数据级融合、特征级融合和目标级融合。
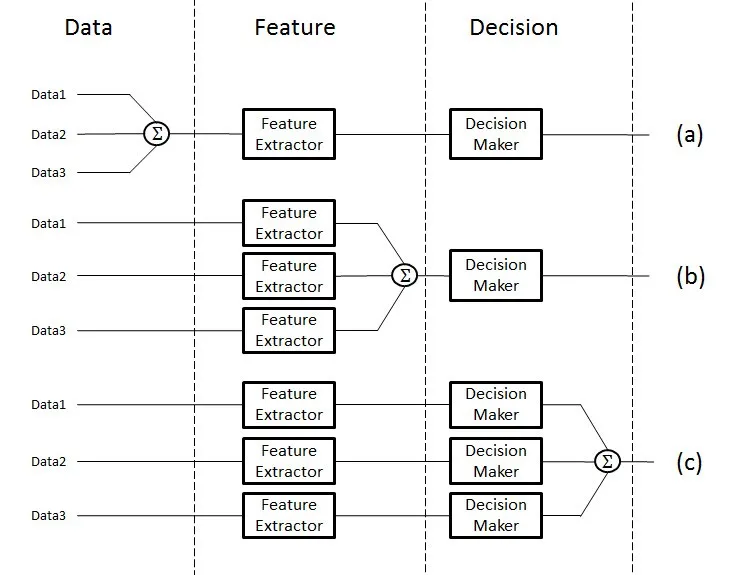
一、数据级融合(Data-Level Fusion):
数据级融合是在预处理阶段将不同模态的原始数据直接合并,适用于高度相关和互补的数据场景。
二、特征级融合(Feature-Level Fusion):
特征级融合是在特征提取之后、决策之前进行的融合。不同模态的数据首先被分别处理,提取出各自的特征表示,然后将这些特征表示在某一特征层上进行融合。广泛应用于图像分类、语音识别、情感分析等多模态任务中。
三、目标级融合(Decision-Level Fusion):
目标级融合是在各单模态模型决策后,将预测结果进行整合以得出最终决策,适用于多模型预测结果综合的场景,如多传感器数据融合、多专家意见综合等。
二、跨模态对齐:准确对应
什么是跨模态对齐(MultiModal Alignment)?跨模态对齐是指利用各种技术手段,使不同模态的数据(例如图像、文本、音频等)在特征、语义或表示层面上能够达到匹配与对应。
跨模态对齐主要分为两大类:显式对齐和隐式对齐。

什么是显示对齐(Explicit Alignment)?直接建立不同模态之间的对应关系,包括无监督对齐和监督对齐。
无监督对齐利用数据自身特性自动发现模态间对应关系,如CCA和自编码器;监督对齐则利用标签信息指导对齐,如多模态嵌入和多任务学习模型。
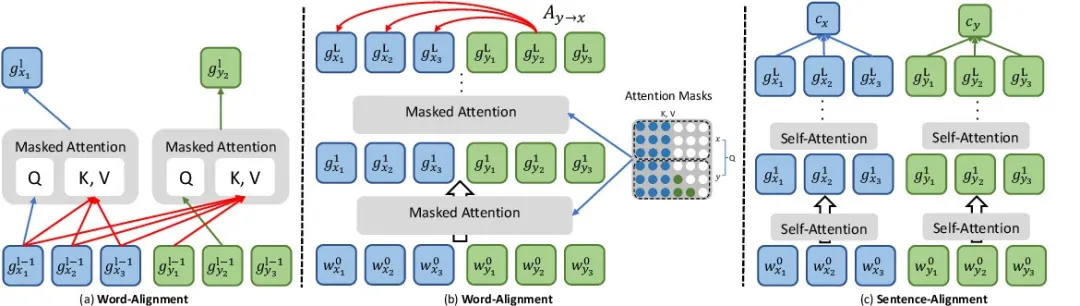
什么是隐式对齐(Implicit Alignment)?不直接建立对应关系,而是通过模型内部机制隐式地实现跨模态的对齐。这包括注意力对齐和语义对齐。
一、注意力对齐
通过注意力机制动态地生成不同模态之间的权重向量,实现跨模态信息的加权融合和对齐。
Transformer模型:在跨模态任务中(如图像描述生成),利用自注意力机制和编码器-解码器结构,自动学习图像和文本之间的注意力分布,实现隐式对齐。
BERT-based模型:在问答系统或文本-图像检索中,结合BERT的预训练表示和注意力机制,隐式地对齐文本查询和图像内容。
二、语义对齐
在语义层面上实现不同模态之间的对齐,需要深入理解数据的潜在语义联系。
图神经网络(GNN):在构建图像和文本之间的语义图时,利用GNN学习节点(模态数据)之间的语义关系,实现隐式的语义对齐。
预训练语言模型与视觉模型结合:如CLIP(Contrastive Language-Image Pre-training),通过对比学习在大量图像-文本对上训练,使模型学习到图像和文本在语义层面上的对应关系,实现高效的隐式语义对齐。

微信扫一扫
关注该公众号
