一文搞懂基于知识图谱的多模态推理
架构师带你玩转AI
2025年02月27日 23:29


一、知识图谱


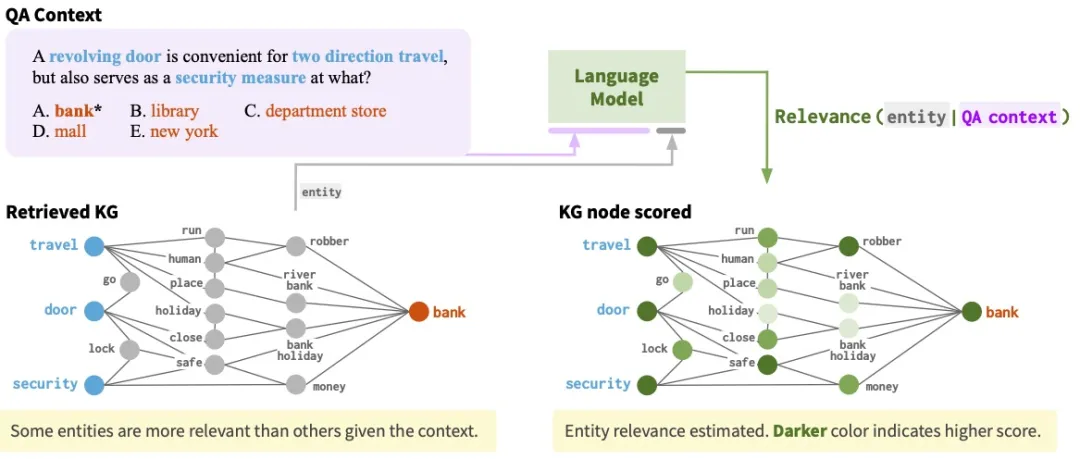
二、多模态推理
什么是多模态推理(Multi-Modal Reasoning)?多模态推理是一种能够同时处理多种类型数据的推理方法,涉及至少两种不同的感知模态,如视觉和语言(图片和文本、视频和语音等),通过整合来自不同模态的数据来增强模型的理解能力和推理能力。
多模态推理突破了传统推理方法仅限于单一信息来源的限制,而是将文本、图像、音频等多种形式的数据融合在一起进行综合分析。

VQA是一个典型的多模态问题,融合了计算机视觉(CV)与自然语言处理(NLP)的技术,计算机需要同时学会理解图像和文字。为了回答某些复杂问题,计算机还需要了解常识,并基于常识进行推理(common sense resoning)。

二、视觉常识推理(Visual Commonsense Reasoning,VCR)
视觉常识推理需要在理解文本的基础上结合图片信息,基于常识进行推理。给定一张图片、图中一系列有标签的bounding box,VCR实际上包含两个子任务:{Q->A}根据问题选择答案;{QA->R}根据问题和答案进行推理,解释为什么选择该答案。
其中VCR数据集由大量的“图片-问答”对组成,主要考察模型对跨模态的语义理解和常识推理能力。
