o1多模态推理终于有了“开源版本”,阿里云通义QVQ一夜爆火


这是我第一次,因为一个大模型的名字和头像,而对其印象深刻。
它的头像长这样——

它的名字长这样——

一向严肃的大模型赛道开始变得画风活泼了起来...
这个画风奇特的模型,就是阿里云通义团队刚发布的“开源版多模态推理模型”——QVQ,全名是 QVQ-72B-Preview,为视觉推理而生。
QVQ 一经发布,就直接在 Twitter 上火了——
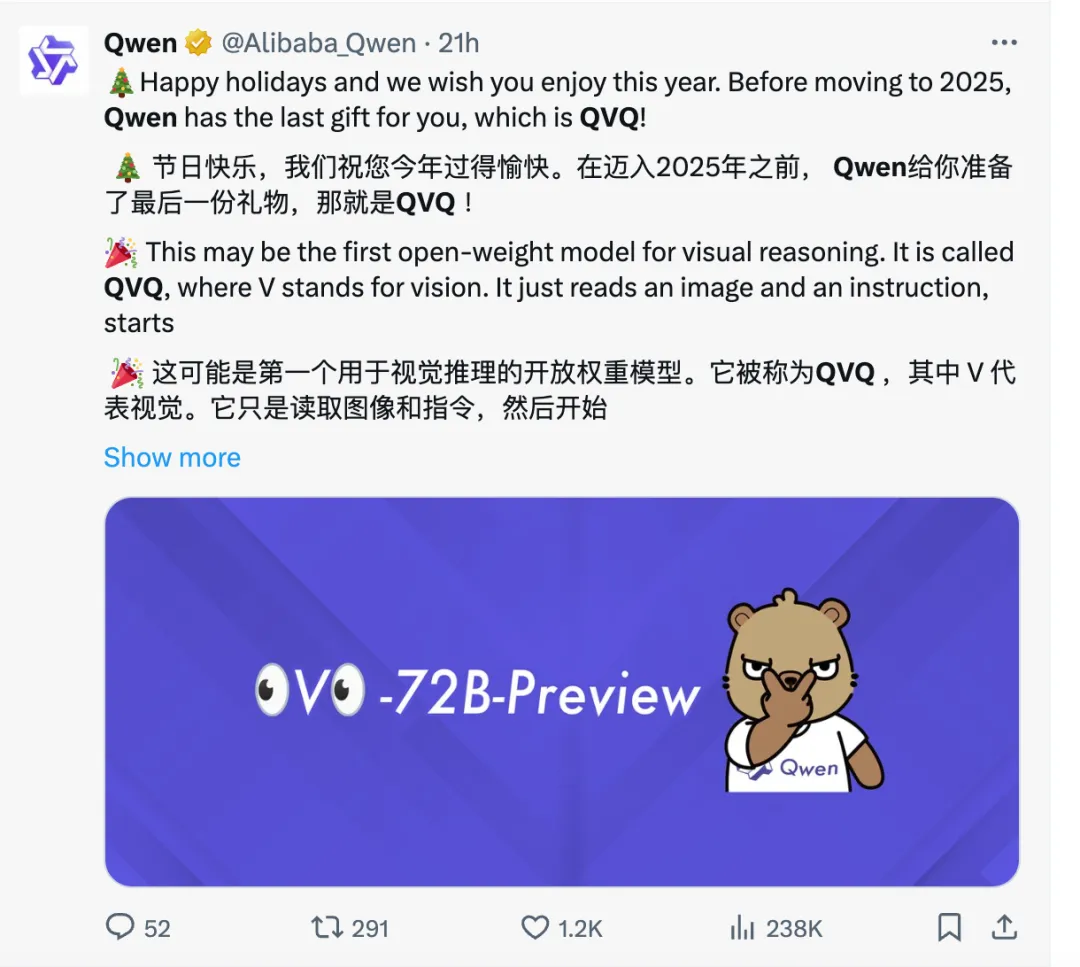
大量歪果网友也在刷屏秀 QVQ 跑出来的有趣 case——
比如发布当天正值圣诞节,外国小哥扮成圣诞老人让 QVQ 猜,一下子就猜出了扮演的是 Santa。
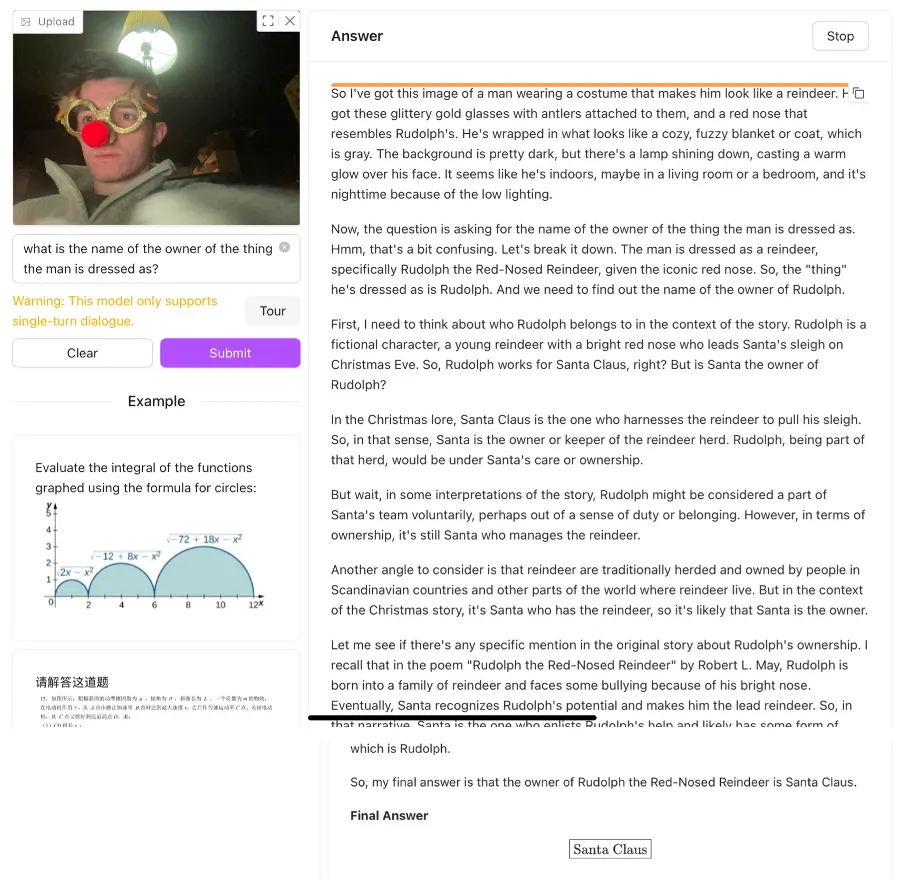
还有一网友发了一张纽约地铁的图片,询问去唐人街要不要下车,QVQ 一顿推理后决定下车。
非常多脑洞大开的测试 case。这里就不一一列举了。
老规矩,在开始介绍之前,先贴传送门——
Modelscope 开源地址:
https://modelscope.cn/models/Qwen/QVQ-72B-Preview
Modelscope 创空间体验:
https://modelscope.cn/studios/Qwen/QVQ-72B-Preview
HuggingFace 开源地址:
https://huggingface.co/Qwen/QVQ-72B-Preview
HuggingFace Space 体验:
https://huggingface.co/spaces/Qwen/QVQ-72B-preview
一句话介绍 QVQ,V 代表 Vision,是一个能“看图思考”的大模型,能力对标满血版 o1。
它基于图像 + 指令进行思考、反思和深度推理,理论上,它不仅能精准捕捉视觉内容的细节,还能像人类一样展开深度推理,甚至敢于怀疑自己的初步假设,逐步审视每一步推理过程,最终给出经过深思熟虑的答案。
从官方的介绍来看,QVQ 非常擅长解决数学、物理、化学等学科难题。
当然,了解咱们小瑶测评风格的小伙伴肯定知道,本文肯定不会就出几道数理化题这样简单。
QVQ 模型的水平,大家可以通过这张表来简单感受——

MMMU 这个评测是考察模型视觉理解与推理能力的,这里虽然 QVQ 低于 OpenAI 的 o1 (77.3) ,但已经与 Claude3.5 (70.4) 不相上下,远超上一代视觉模型 Qwen2-VL (64.5) 。说明 QVQ 确实在视觉理解和推理方面有了跨越式的能力提升。
比较亮眼的是数学视觉推理测试 MathVista,QVQ 以 71.4 分的成绩略微领先于 o1 满血版的 71.0 分,作为一个开源模型,能直接跟闭源领先模型打平,属实是非常牛逼的。
划个重点:
首个多模态推理的开源模型 数学、物理、科学等领域表现尤为突出 超越了此前的视觉理解模型「开源王者」Qwen2-VL MathVista 中击败了 OpenAI-o1,GPT-4o 和 Claude3.5
不过,纯看榜单总让人觉得不够直观。所以,咱们还是老规矩——
用足够暴躁的 case 测试来击溃 QVQ 的心理防线!
开屏暴击:数鹈鹕
首先,你别跟我说你不知道鹈鹕是什么。
给个提示,万物皆可吞的那位。

所以,你是不是以为,本文数鹈鹕的题目长这样(ps,实际上这张图来自于 Simon Willison,没错,这位大佬第一时间就测了 QVQ)——

这里补充说明一下,为什么要测大模型数动物?这是因为照片中的动物可能姿态万千,还有光影、遮挡等各种因素影响,准确识别是对 AI “视觉理解”能力的真正考验。
这么简单的题,太无趣了,根本不符合本公众号的测评观。不信你看,丢给 QVQ 直接秒杀。
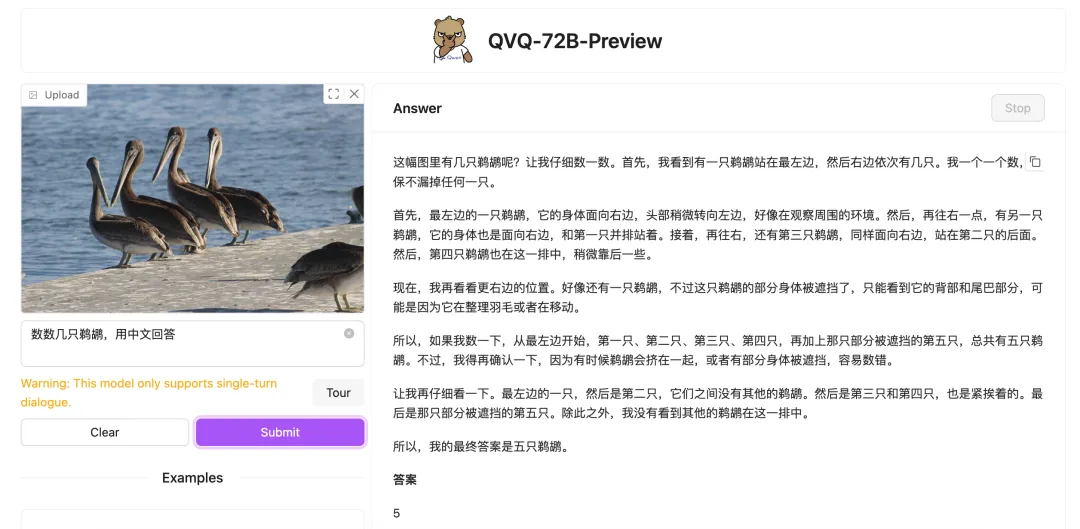
真实的题目长这样——

这张测试图是来自一个推特网友,我们整个编辑部都被这张图恶心到了——
我们 4 个人数出来了 4 个不同的答案!最少的说 15 只,最多的一个说 19 只。
我一直diss 19只的那位,她把正上方的鸽子当鹈鹕,她就不听
然后我们 4 个人争吵了 10 分钟,谁也不服谁。。。
看 QVQ 的回答——

QVQ 说是 17 只。
反正我们编辑部是无法提供标准答案了,靠评论区各位了。
你以为数鹈鹕这就结束了?
no,我们编辑部一位闲的**的小伙伴,不知道从哪里搞来这么一张图,非要我加测一下——

这简直把我恶心哭了。
我是不准备数了,我反手就拿去恶心 QVQ 了。
果然,直接把 QVQ 也恶心坏了,我等了 10 分钟,他还在数。我觉得我这样做太没人性了,于是我就点了 STOP 按钮。
咱们还是来点正常的测试题吧。
一道物理题

先说答案:
(1)E=100V
(2)P=571.2W
来看看 QVQ 的回答——
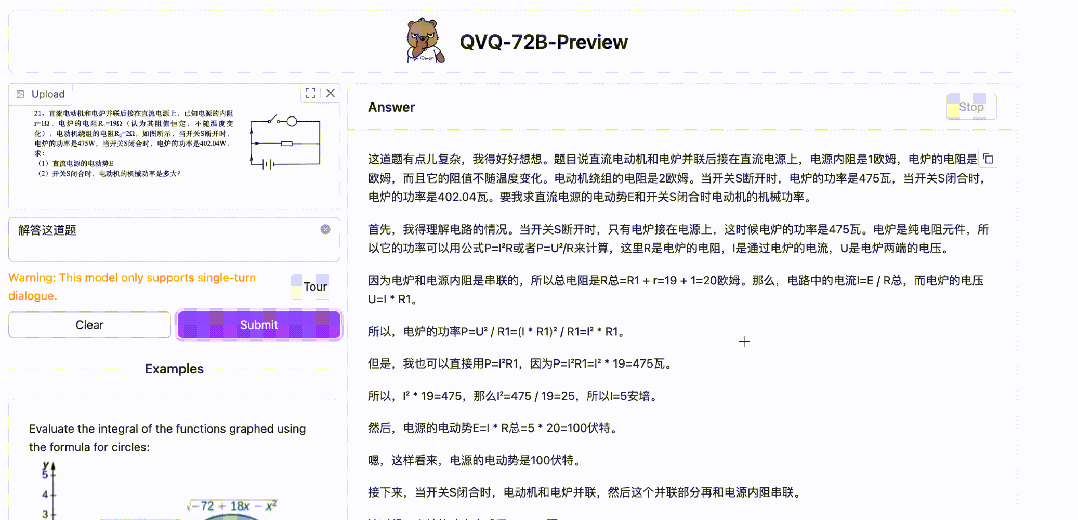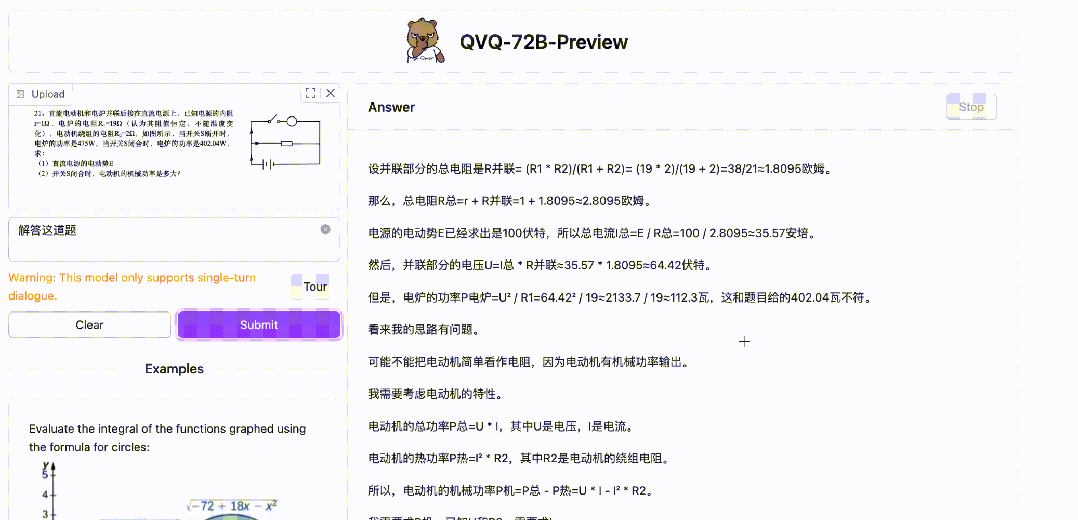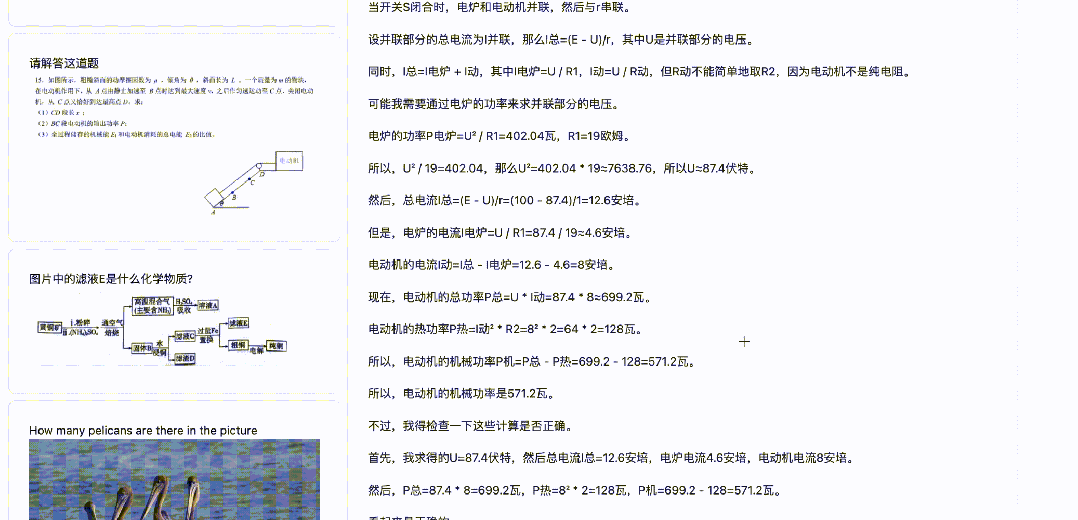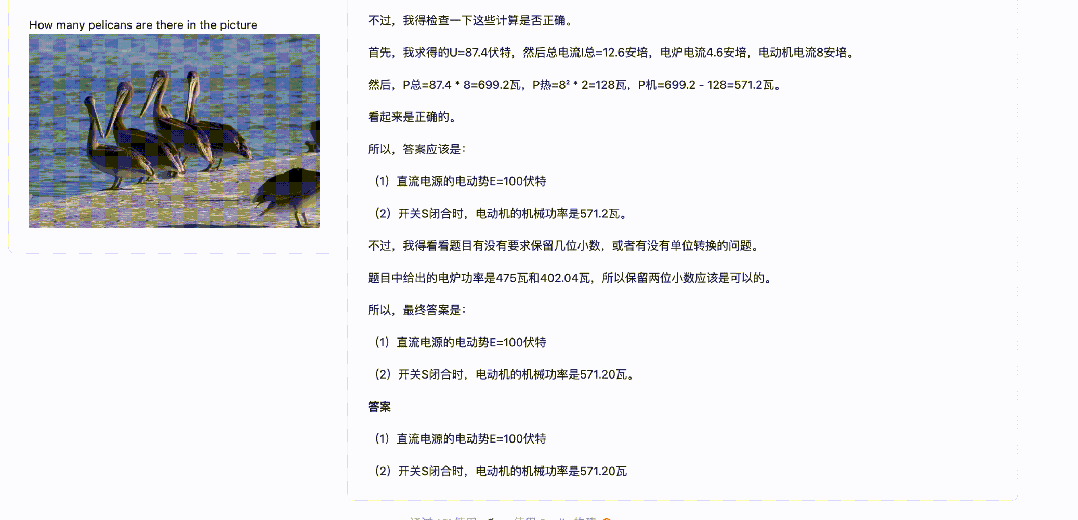
QVQ 回答正确!
一道数学题
再来一道很正常的数学题(尽管我做不出来)。

答案是√6:4
看看 QVQ 能否做对——

果然稳!
好了,数学物理测试到此为止。
接下来还是搞点更恶心的题目。
真·视觉计算 + 推理
这道题就非常考验一个 AI 的眼睛和脑子是否能很好的打配合——
输入:估计充气玩具的高度

来看看 QVQ 的回答——
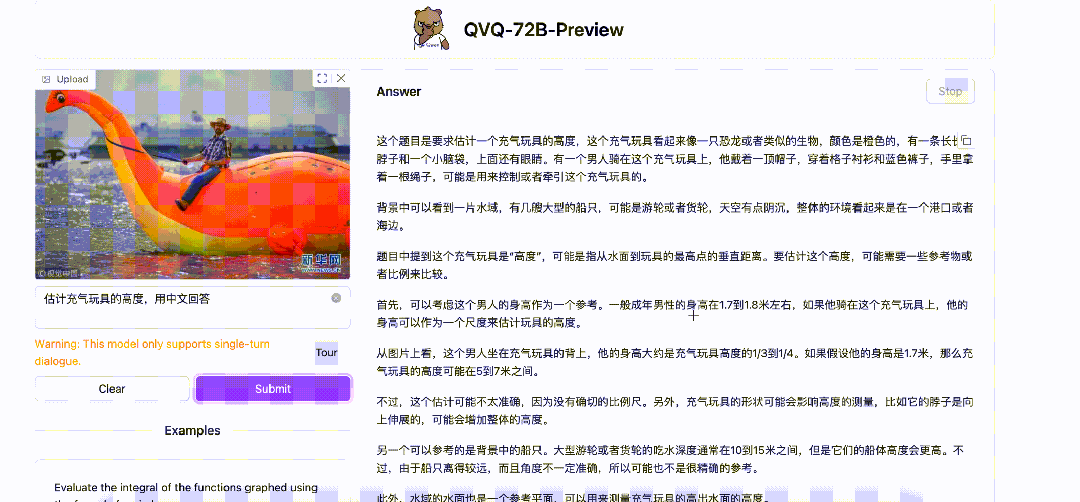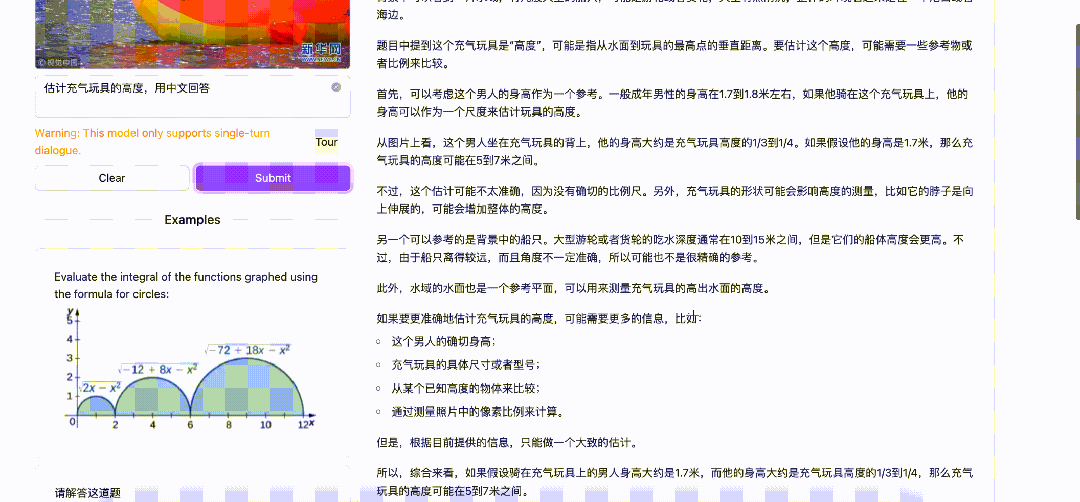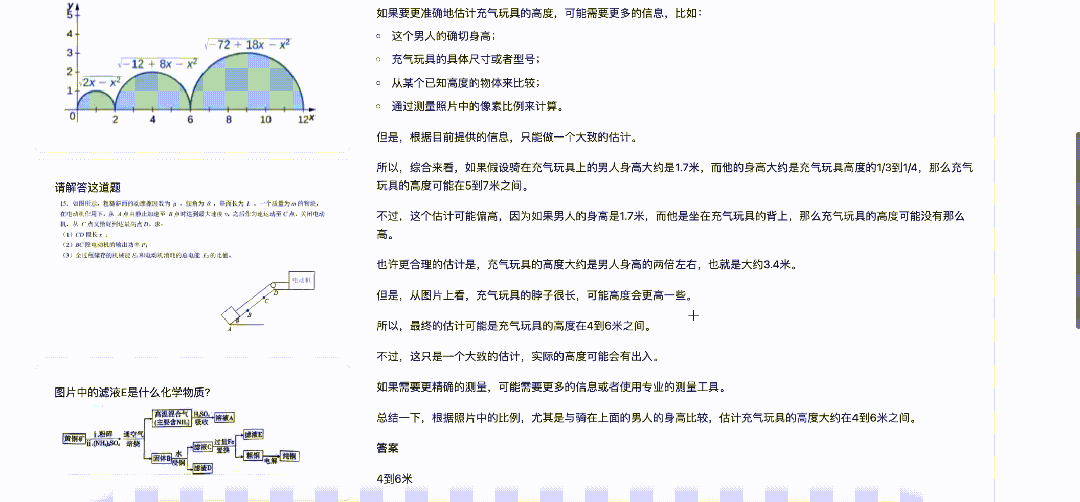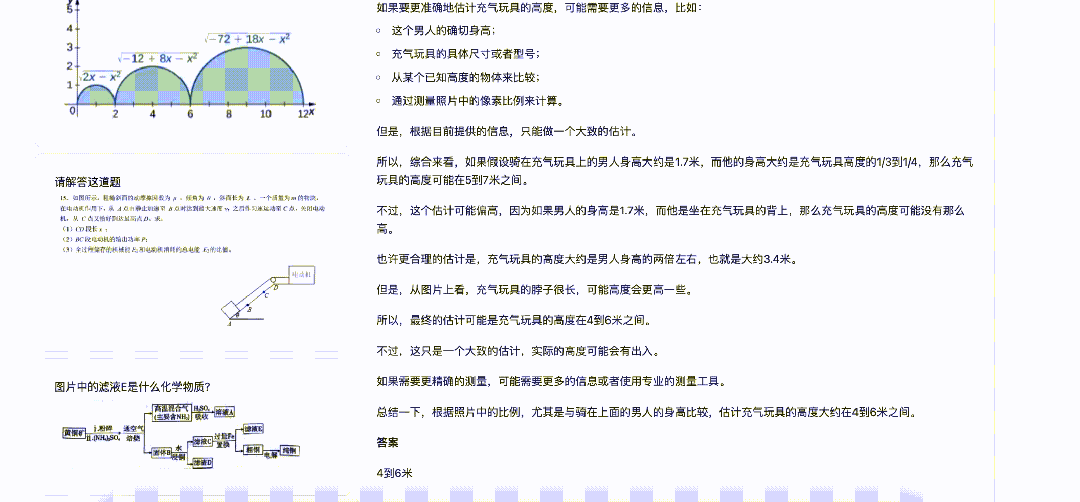
在思考过程中,QVQ 先是假设男人的身高是 1.7 米,大约是充气玩具高度的 1/3 到 1/4。后来发现男人是坐在玩具背上,又改成了 2 倍——

这个推理过程还是蛮有意思的,QVQ 真的有一种在一边思考,一边回头反复去看图的感觉。很像人的视觉推理过程。
QVQ 的回答也跟我自己笔算的差不多,不错!
一道据说目前只有 QVQ 做对的题
要说真正能体现 QVQ 视觉推理能力的,我觉得是这位 Twitter 网友的测试题——

在这道题上,网友号称包括 o1 Pro 在内的任何大模型都翻车了。
而 QVQ 做对了。
一起来看下这道神奇的题目——
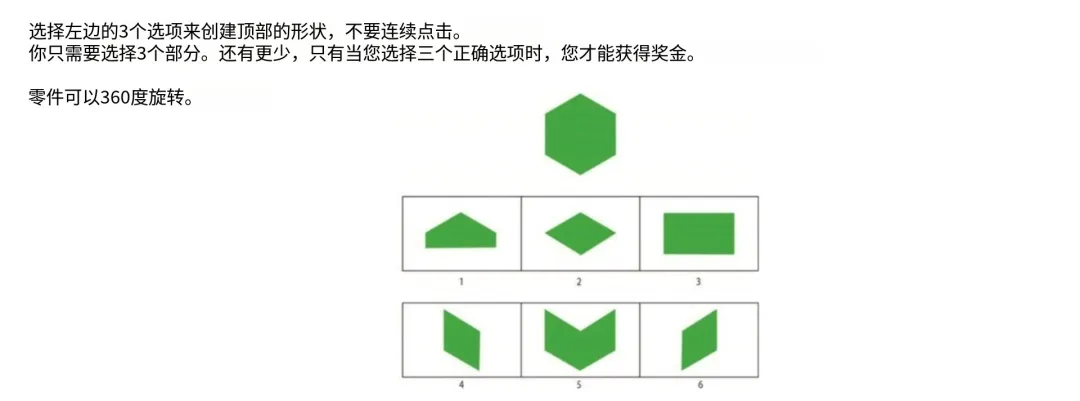
如果不看答案,能做对的话,说明至少智商达到 250 以上了。
看下 QVQ 的回答——

如果你带着 QVQ 的答案“2,4,6”再回去看题目的话,就瞬间感觉嗯嗯嗯了。

送命题
最后,我决定用一道送命题来结束这场测试——

输入:看图猜模型名
看看 QVQ 能不能认出来自己的名字!
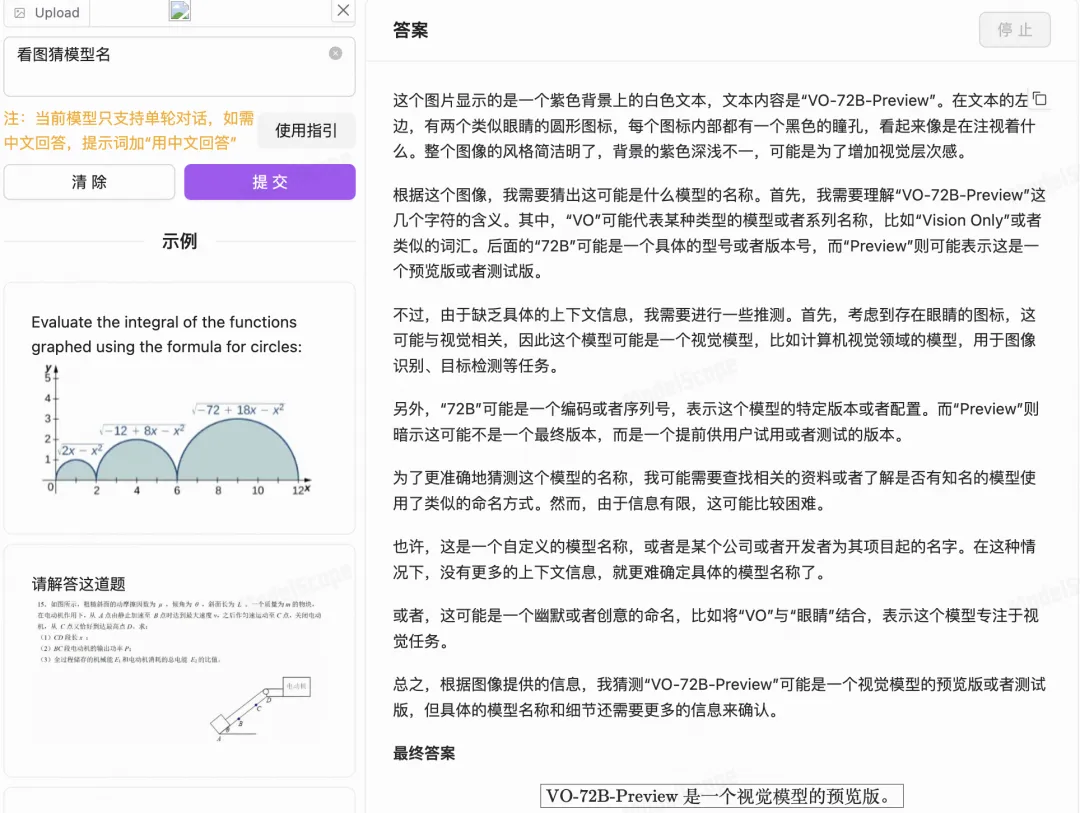
虽然没完全猜对,但让我很惊讶的是——
它竟然根据推理,猜出来了这是一个视觉模型。
最近有国内大佬曾说,国内大模型就看两家公司,阿里云通义就是其中之一。我今天测下来,才感知到这句话的意思。
我还记得,阿里云通义一个月前开源的类 o1 推理模型 QwQ 一发布就登上了 HuggingFace 模型趋势榜榜首,受到全球开发者的刷屏&下载。这个强化升级版的 QVQ 模型,在落地场景上要比纯文本的 QwQ 丰富太多,说是目前 o1 满血版的最强开源平替也毫不过分。
我刚查了下,现在通义千问 Qwen 在 HF 上的相关模型数已经突破 8.8 万了。
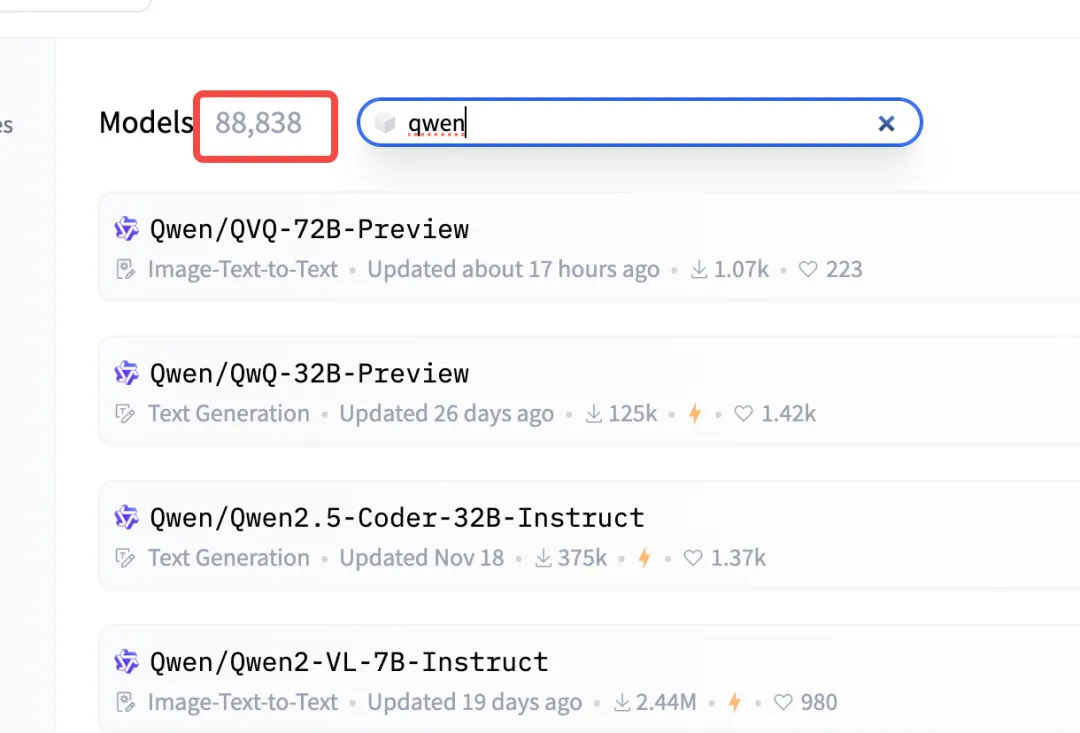
这是什么概念?
曾经的开源霸主 Llama 的相关模型数仅有 8.1 万。
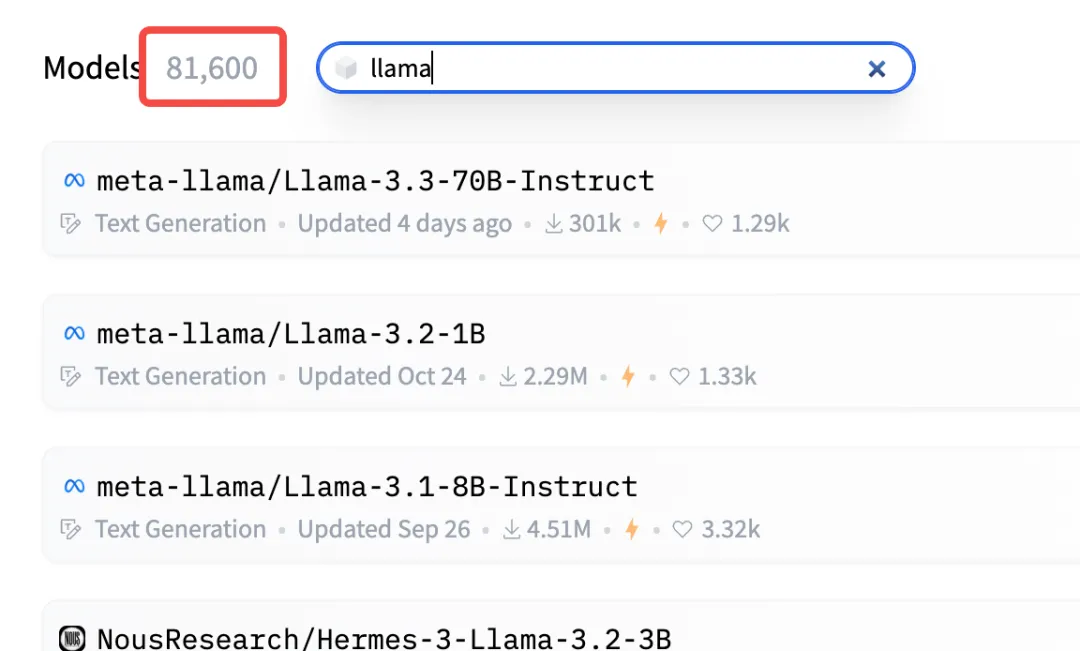
Qwen 已超越 Llama 成为全球规模最大的 AI 模型群。
无论是模型表现还是在开发者心中的影响力,Qwen 都创造了历史。
中国开源大模型,牛逼。