一文搞懂DeepSeek - 多头注意力(MHA)和多头潜在注意力(MLA)

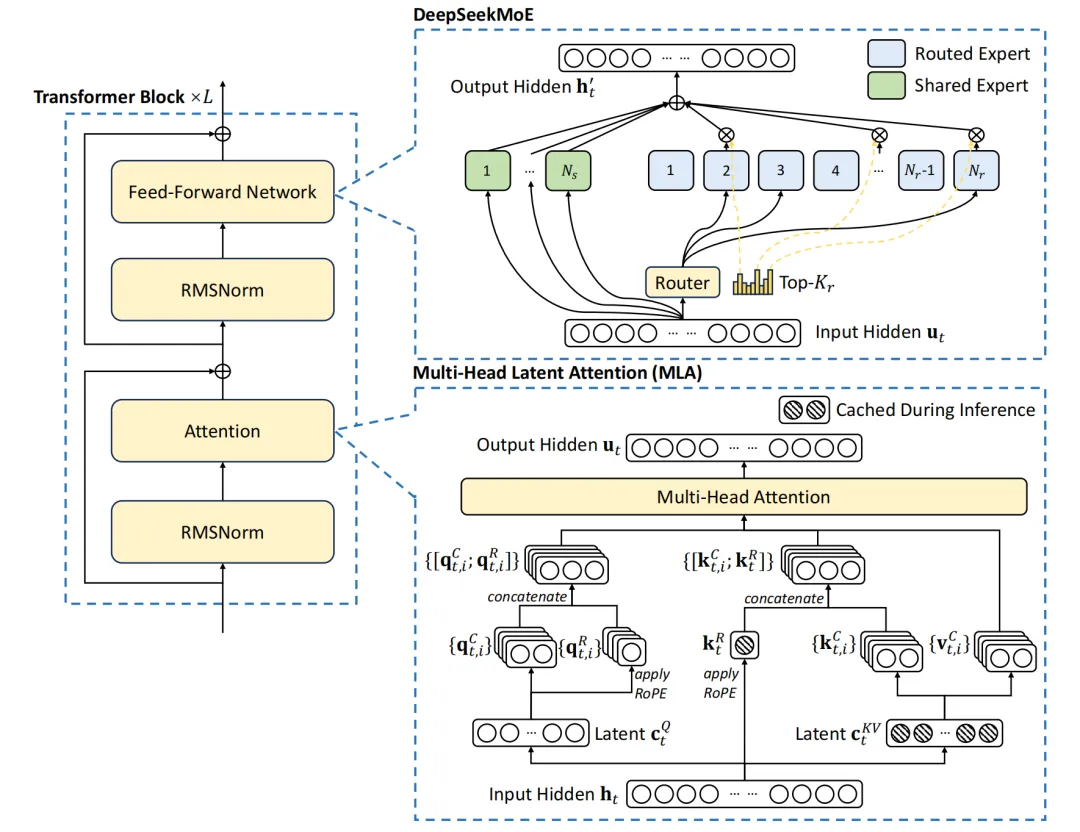
DeepSeek-V3的基本架构仍然基于Transformer框架,为了实现高效推理和经济高效的训练,DeepSeek-V3还采用了MLA(多头潜在注意力)。
MHA(多头注意力)通过多个注意力头并行工作捕捉序列特征,但面临高计算成本和显存占用;MLA(多头潜在注意力)则通过低秩压缩优化键值矩阵,降低显存占用并提高推理效率。
一、多头注意力(MHA)
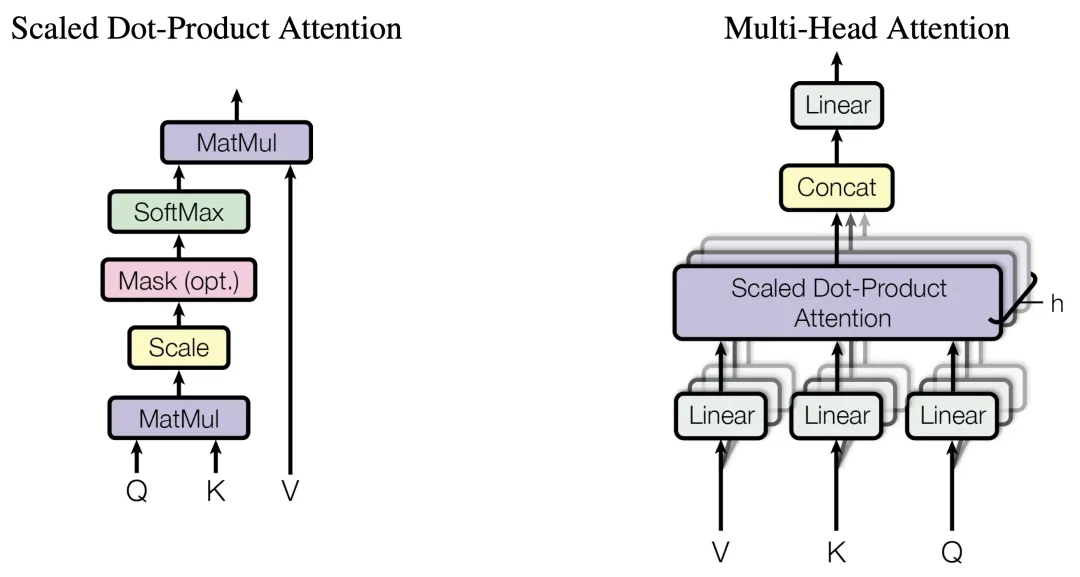
输入变换:输入序列首先通过三个不同的线性变换层,分别得到查询(Query)、键(Key)和值(Value)矩阵。这些变换通常是通过全连接层实现的。
分头:将查询、键和值矩阵分成多个头(即多个子空间),每个头具有不同的线性变换参数。
注意力计算:对于每个头,都执行一次缩放点积注意力(Scaled Dot-Product Attention)运算。具体来说,计算查询和键的点积,经过缩放、加上偏置后,使用softmax函数得到注意力权重。这些权重用于加权值矩阵,生成加权和作为每个头的输出。
拼接与融合:将所有头的输出拼接在一起,形成一个长向量。然后,对拼接后的向量进行一个最终的线性变换,以整合来自不同头的信息,得到最终的多头注意力输出。

二、多头潜在注意力(MLA)
在传统的Transformer架构中,多头注意力(MHA)机制允许模型同时关注输入的不同部分,每个注意力头都独立地学习输入序列中的不同特征。然而,随着序列长度的增长,键值(Key-Value,KV)缓存的大小也会线性增加,这给模型带来了显著的内存负担。为解决MHA在高计算成本和KV缓存方面的局限性,DeepSeek引入了多头潜在注意力(MLA)。
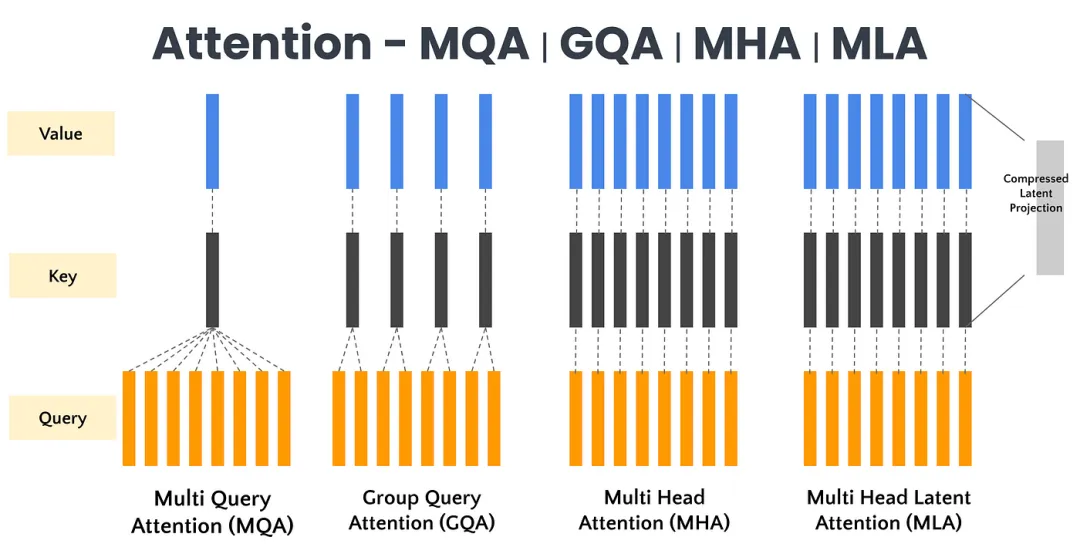
多头潜在注意力(MLA)技术创新是什么?多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键值(KV)矩阵,显著减少了内存消耗并提高了推理效率。
低秩联合压缩键值:MLA通过低秩联合压缩键值(Key-Value),将它们压缩为一个潜在向量(latent vector),从而大幅减少所需的缓存容量。这种方法不仅减少了缓存的数据量,还降低了计算复杂度。
优化键值缓存:在推理阶段,MHA需要缓存独立的键(Key)和值(Value)矩阵,这会增加内存和计算开销。而MLA通过低秩矩阵分解技术,显著减小了存储的KV(Key-Value)的维度,从而降低了内存占用。
MLA通过“潜在向量”来表达信息,避免了传统注意力机制中的高维数据存储问题。利用低秩压缩技术,将多个查询向量对应到一组键值向量,实现KV缓存的有效压缩,使得DeepSeek的KV缓存减少了93.3%。